|
Дерево - специальный вид направленного графа. Графы - структуры данных, состоящие из узлов связанных дугами. Кажая дуга показывает однонаправленную связь между двумя узлами. В организационной диаграмме, узлы - сотрудники, а каждая дуга описывает подчинения. В перечне материалов, узлы - модули (в конечном счете, показываемые до индивидуальных частей), и дуги описывают отношение "сделан из".
Вершина дерева называется корнем. В организационной диаграмме, это самый большой начальник; в перечне материалов, это собранная деталь. Двоичное дерево - это дерево, в котором узел может иметь не более двух потомков; В общем случае, n-мерное дерево - то, в котором узел может иметь не больше чем n узлов - потомков.
Узлы дерева, которые не имеют поддеревьев, называются листьями. В перечне материалов, это - минимальные части, на которые может быть разобрана деталь. Потомки, или дети, родительского узла - все узлы в поддереве, имееющего родительский узел коренем.
Деревья часто изображаются как диаграммы. (См. рисунок 1) Другой путь представления деревьев состоит в том, чтобы показывать их как вложенные множества (см. рисунок 2); Это основа для используемого мной представления деревьев в SQL в виде вложенных множеств.
В SQL, любые отношения явно явно описываются данными.. Типичный способ представления деревьев состоит в том, чтобы поместить матрицу смежности в таблицу. Т.е. один столбец - родительский узел, и другой столбец в той же самой строке - дочерний узел (пара представляет собой дугу в графе). Например, рассмотрим организационную диаграмму компании с шестью сотрудниками:
CREATE TABLE Personnel(
emp CHAR(20) PRIMARY KEY,
boss CHAR(20) REFERENCES Personnel(emp),
salary DECIMAL(6,2) NOT NULL
);
Personnel:
emp boss salary
==========================
'Jerry' NULL 1000.00
'Bert' 'Jerry' 900.00
'Chuck' 'Jerry' 900.00
'Donna' 'Chuck' 800.00
'Eddie' 'Chuck' 700.00
'Fred' 'Chuck' 600.00
Эта модель имеет преимущества и недостатки. ПЕРВИЧНЫЙ КЛЮЧ - emp, но столбец boss - функционально зависит от него, следовательно мы имеем проблемы с нормализацией. REFERENCES не даст вам возможность указать начальником, того кто не является сотрудником. Однако, что произойдет, когда 'Jerry' изменяет имя на 'Geraldo', чтобы получить телевизионное ток-шоу? Вы также должны сделать каскадные изменения в строках 'Bert' и 'Chuck'.
Другой недостаток этой модели - то трудно вывести путь. Чтобы найти имя босса для каждого служащего, используется самообъединяющийся запрос, типа:
SELECT B1.emp, 'bosses', E1.emp
FROM Personnel AS B1, Personnel AS E1
WHERE B1.emp = E1.boss;
Но кое-что здесь отсутствует. Этот запрос дает Вам только непосредственных начальников персонала. Босс Вашего босса также имеет власть по отношению к Вам, и так далее вверх по дереву. Чтобы вывести два уровня в дереве, Вам необходимо написать более сложный запрос самообъединения, типа:
SELECT B1.emp, 'bosses', E2.emp
FROM Personnel AS B1, Personnel AS E1, Personnel AS E2
WHERE B1.emp = E1.boss AND E1.emp = E2.boss;
Чтобы идти более чем на два уровня глубже в дереве, просто расширяют образец:
SELECT B1.emp, 'bosses', E3.emp
FROM Personnel AS B1, Personnel AS E1,
Personnel AS E2, Personnel AS E3
WHERE B1.emp = E1.boss
AND E1.emp = E2.boss
AND E2.emp = E3.boss;
К сожалению, Вы понятия не имеете насколько глубоко дерево, так что Вы должны продолжать расширять этот запрос, пока Вы не получите в результате пустое множество.
Листья не имеют потомков. В этой модели, их довольно просто найти: Это сотрудники, не являющиеся боссом кому либо еще в компании:
SELECT *
FROM Personnel AS E1
WHERE NOT EXISTS(
SELECT *
FROM Personnel AS E2
WHERE E1.emp = E2.boss);
У корня дерева boss - NULL:
SELECT *
FROM Personnel
WHERE boss IS NULL;
Реальные проблемы возникают при попытке вычислить значения вверх и вниз по дереву. Как упражнение, напишите запрос, суммирующий жалованье каждого служащего и его/ее подчиненных; результат:
Total Salaries
emp boss salary
==========================
'Jerry' NULL 4900.00
'Bert' 'Jerry' 900.00
'Chuck' 'Jerry' 3000.00
'Donna' 'Chuck' 800.00
'Eddie' 'Chuck' 700.00
'Fred' 'Chuck' 600.00
Множественная модель деревьев.
Другой путь представления деревьев состоит в том, чтобы показать их как вложенные множества. Это более подходящая модель, т.к. SQL - язык, ориентированный на множества. Корень дерева - множество, содержащее все другие множества, и отношения предок-потомок описываются принадлежностью множества потомков множеству предка.
Имеются несколько способов преобразования организационной диаграммы во вложенные наборы. Один путь состоит в том, чтобы вообразить, что Вы перемещаете подчиненные "овалы" внутри их родителей, использующих линии края как веревки. Корень - самый большой овал и содержит все другие узлы. Листья - самые внутренние овалы, ничего внутри не содержащие, и вложение соответствует иерархическим отношениям. Это - естественное представление модели "перечень материалов", потому что заключительный блок сделан физически из вложенных составляющих, и разбирается на отдельные части.
Другой подход состоит в том, чтобы представить небольшой червь, ползающий по "узлам и дугам" дерева. Червь начинает сверху, с кореня, и делает полную поездку вокруг дерева.
Но теперь давайте представим более сильный червь со счетчиком, который начинается с единицы. Когда червь прибывает в узел, он помещает число в ячейку со стороны, которую он посетил и увеличивает счетчик. Каждый узел получит два номера, одино для правой стороны и одино для левой стороны.
Это дает предсказуемые результаты, которые Вы можете использовать для формирования запросов. Таблица Personnel имеет следующий вид, с левыми и правыми номерами в виде:
CREATE TABLE Personnel(
emp CHAR(10) PRIMARY KEY,
salary DECIMAL(6,2) NOT NULL,
left INTEGER NOT NULL,
right INTEGER NOT NULL);
Personnel
emp salary left right
==============================
'Jerry' 1000.00 1 12
'Bert' 900.00 2 3
'Chuck' 900.00 4 11
'Donna' 800.00 5 6
'Eddie' 700.00 7 8
'Fred' 600.00 9 10
Корень всегда имеет 1 в левом столбце и удвоенное число узлов (2*n) в правом столбце. Это просто понять: червь должен посетить каждый узел дважды, один раз с левой стороны и один раз с правой стороны, так что заключительный количество должено быть удвоенное число узлов во всем дереве.
В модели вложенных множеств, разность между левыми и правыми значениями листьев - всегда 1. Представте червя, поворачивающегся вокруг листа, пока он ползет по дереву. Поэтому, Вы можете найти все листья следующим простым запросом:
SELECT *
FROM Personnel
WHERE (right - left) = 1;
Вы можете использовать такую уловку, для ускорения запросов: постройте уникальный индекс по левому столбцу, затем перепишите запрос, чтобы воспользоваться преимуществом индекса:
SELECT *
FROM Personnel
WHERE left = (right - 1);
Причина увеличения производительности в том, что SQL может использовать индекс по левому столбцеу, когда он не испорльзуется в выражении. Не используйте (left - right) = 1, потому что это дает воспользоваться преимуществами индекса.
В модели вложенных - имножеств, пути показываются как вложенные множества, которые представлены номерами вложенных множеств и предикатами BETWEEN. Например, чтобы определить всех боссов определенного сотрудника необходимо написать:
SELECT :myworker, B1.emp, (right - left) AS height
FROM Personnel AS B1, Personnel AS E1
WHERE E1.left BETWEEN B1.left AND B1.right
AND E1.right BETWEEN B1.left AND B1.right
AND E1.emp = :myworker;
Чем больше height, тем дальше по иерархии босс от служащего. Модель вложенных множеств использует факт, что каждое содержащее другие множество является большим в размере (где размер = (right - left)) чем множества, в нем содержащиеся. Очевидно, корень будет всегда иметь самый большой размер.
Уровень, число дуг между двумя данными узлами, довольно просто вычислить. Например, чтобы найти уровни между заданным рабочим и менеджером, Вы могли бы использовть:
SELECT E1.emp, B1.emp, COUNT(*) - 1 AS levels
FROM Personnel AS B1, Personnel AS E1
WHERE E1.left BETWEEN B1.left AND B1.right
AND E1.right BETWEEN B1.left AND B1.right
AND E1.node = :myworker
AND B1.node = :mymanager;
(COUNT(*) - 1) используется для того, чтобы удалить двойной индекс узла непосредственно как нахождение на другом уровне, потому что узел - нулевые уровни, удаленные из себя.
Вы можете построить другие запросы из этого шаблона. Например, чтобы найти общих боссов двух служащих, объединяют пути и находят узлы который имеют (COUNT(*) > 1). Чтобы найти самых близких общих предков двух узлов, объединяют пути, находят узлы, которые имеют (COUNT(*) > 1), и выбирают с наименьшей глубиной.
| Рисунок 1. |
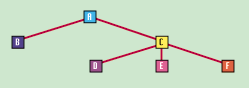 |
Вершина дерева называется корнем. Узлы дерева, которые не имеют поддеревьев, называются листьями. Потомки родительского узла - узлы в поддервья, имеющие корнем родительский узел. |
| Рисунок 2. |
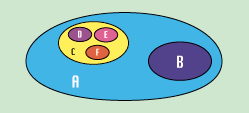 |
Другой путь представления деревьев состоит в том, чтобы показать их как вложенные множества. Это более подходящая модель, т.к. SQL - язык, ориентированный на множества. Корень дерева - множество, содержащее все другие множества, и отношения предок-потомок описываются принадлежностью множества потомков множеству предка. |
© Joe Celko
DBMS Online - March 1996
Translated by SDM
Множественная модель деревьев. Часть 2.
Я предполагаю, что Вы имеете перед собой статью за март 1996, так что я не буду повторяться. Множественная модель деревьев имеет некоторые свойства, которые я не упоминал в прошлом месяце. Но сначала, давайте создадим таблицу (см. Листинг 1) для хранения информации о персонале. Я буду повсюду обращаться к этой таблице в остальной части этой статьи.
Дерево на рисунке 1 представлено как A) граф и Б) вложенные множества. Направление показываетя вложением, то есть Вы знаете, что кто-то - подчиненный кого-то еще в иерархии компании, если что левые и правые номера множества этого человека- между таковыми их боссов.
Другое свойство, которое я не упоминал в последний раз - то, что потомки- упорядоченны, т.е. Вы можете использовать номера элементов множества, чтобы упорядочить потомков. Это свойство отсутствует в модели матрицы смежности, которая не имеет никакого упорядочения среди потомков. Вы можете использовать этот факт при вставке, обновлении, или удалении узлов в дереве.
Одним из свойств дерева является то, что оно является графом без циклов. То есть никакой путь не замыкается, чтобы поймать Вас в бесконечной петле, когда Вы следуете им в дереве. Другое свойство- то, что всегда имеется путь от корня до любого другого узла в дереве. В модели вложенноых множеств, пути показываются как вложенные множества, которые представлены номерами множеств и предикатами BETWEEN. Например, чтобы выяснить всех менеджеров, которым должен отчитываться рабочий, вы можете написать:
SELECT 'Mary',
P1.emp, (P1.rgt - P1.lft) AS size
FROM Personnel AS P1, Personnel AS P2
WHERE P2.emp = 'Mary'
AND P2.lft BETWEEN P1.lft AND P1.rgt;
Mary emp size
==== === ====
Mary Albert 27
Mary Charles 13
Mary Fred 9
Mary Jim 5
Mary Mary 1
Заметьте, что, когда size = 1, Вы имеете дело С Мэри как с ее собственным боссом. Вы можете исключить этот случай.
Модель вложенная множеств использует факт, что каждый вешний набор имеет больший size (size = right - left) чем множества, которые оно содержит. Очевидно, корень будет всегда иметь самый большой size. JOIN и ORDER BY не нужны в модели вложенных множеств, как модели графа смежности. Плюс, результаты не зависят от порядка, в котором отображаются строки.
Уровень узла - число дуг между узлом и корнем. Вы можете вычислять уровень узла следующим запросом:
SELECT P2.emp, COUNT(*) AS level
FROM Personnel AS P1, Personnel AS P2
WHERE P2.lft BETWEEN P1.lft AS P2
GROUP BY P2.emp;
Этот запрос находит уровни среди менеджеров, следующим образом:
emp level
=== =====
Albert 1
Bert 2
Charles 2
Diane 2
Edward 3
Fred 3
George 3
Heidi 3
Igor 4
Jim 4
Kathy 4
Larry 4
Mary 5
Ned 5
В некоторых книгах по теории графов, корень имеет нулевой уровнь вместо первого. Если Вам нравится это соглашение, используйте выражение "(COUNT(*)-1)".
Самообъединения в комбинации с предикатом BETWEEN- основной шаблон для других запросов.
Агрегатные функции в деревьях.
Получение простой суммы зарплаты подчиненных менеджера работает на том же самом принципе. Заметьте, что эта общая сумма будет также включать зарплату босса:
SELECT P1.emp, SUM(P2.salary) AS payroll
FROM Personnel AS P1, Personnel AS P2
WHERE P2.lft BETWEEN P1.lft AND P1.rgt
GROUP BY P1.emp;
emp payroll
=== =======
Albert 7800.00
Bert 1650.00
Charles 3250.00
Diane 1900.00
Edward 750.00
Fred 1600.00
George 750.00
Heidi 1000.00
Igor 500.00
Jim 300.00
Kathy 100.00
Larry 100.00
Mary 100.00
Ned 100.00
Следующий запрос будет брать уволенного служащего как параметр и удалять поддерево, расположенное под ним/ней. Уловка в этом запросе - то, что Вы используете ключ, но Вы должны заставить работать левые и правые значения. Ответ - набор скалярных подзапросов:
DELETE FROM Personnel
WHERE lft BETWEEN
(SELECT lft FROM Personnel WHERE emp = :downsized)
AND
(SELECT rgt FROM Personnel WHERE emp = :downsized);
Проблема состоит в том, что после этого запроса появляются промежутки в последовательности номеров множеств. Это не мешает выполнять большинство запросов к дереву, т.к. свойство вложения сохранено. Это означает, что Вы можете использовать предикат BETWEEN в ваших запросах, но другие операции, которые зависят от плотности номеров, не будут работать в дереве с промежутками. Например, Вы не сможете находить листья, используя предикат (right-left=1), и не сможете найти число узлов в поддереве, используя значения left и right его корня.
К сожалению, Вы потеряли информацию, которая будет очень полезна в закрытии тех промежутков - а именно правильные и левые номера корня поддерева. Поэтому, забудьте запрос, и напишите вместо этого процедуру:
CREATE PROCEDURE DropTree (downsized IN CHAR(10) NOT NULL)
BEGIN ATOMIC
DECLARE dropemp CHAR(10) NOT NULL;
DECLARE droplft INTEGER NOT NULL;
DECLARE droprgt INTEGER NOT NULL;
--Теперь сохраним данные поддерева:
SELECT emp, lft, rgt
INTO dropemp, droplft, droprgt
FROM Personnel
WHERE emp = downsized;
--Удаление, это просто...
DELETE FROM Personnel
WHERE lft BETWEEN droplft and droprgt;
--Теперь уплотняем промежутки:
UPDATE Personnel
SET lft = CASE
WHEN lft > droplf
THEN lft - (droprgt - droplft + 1)
ELSE lft END,
rgt = CASE
WHEN rgt > droplft
THEN rgt - (droprgt - droplft + 1)
ELSE rgt END;END;
Реальная процедура должна иметь обработку ошибок, но я оставляю это как упражнение для читателя.
Удаление одиночного узла в середине дерева тяжелее чем удаление полных поддеревьев. Когда Вы удаляете узел в середине дерева, Вы должны решить, как заполнить отверстие. Имеются два пути. Первый метод к повышает одного из детей к позиции первоначального узла (предположим, что отец умирает, и самый старший сын занимает бизнес, как показано на рисунке 2). Самый старший потомок всегда показывается как крайний левый дочерний узел под родителем. Однако с этой этой операцией имеется проблема. Если старший ребенок имеет собственнх детей, Вы должны решить, как обработать их, и так далее вниз по дереву, пока Вы не добираетесь к листу.
Второй метод для удаления одиночного узла в середине дерева состоит в том, чтобы подключить потомков к предку первоначального узла (можно сказать, что мамочка умирает, и дети приняты бабушкой), как показано на рисунке 3. Это получается автоматически во модели вложенных множеств, Вы просто удаляете узел, и его дети уже содержатся в узлах его предка. Однако, Вы должны быть осторожны, при закрытии промежутка, оставленного стиранием. Имеется различие в изменении нумерации потомков удаленного узла и изменения нумерации узлов справа. Ниже - процедура выполняющая это:
CREATE PROCEDURE DropNode (downsized IN CHAR(10) NOT NULL)
BEGIN ATOMIC
DECLARE dropemp CHAR(10) NOT NULL;
DECLARE droplft INTEGER NOT NULL;
DECLARE droprgt INTEGER NOT NULL;
--Теперь сохраним данные поддерева:
SELECT emp, lft, rgt
INTO dropemp, droplft, droprgt
FROM Personnel
WHERE emp = downsized;
--Удаление, это просто...
DELETE FROM Personnel
WHERE emp = downsized;
--Теперь уплотняем промежутки:
UPDATE Personnel
SET lft = CASE
WHEN lft BETWEEN droplft AND droprgt THEN lft - 1
WHEN lft > droprgt THEN lft - 2
ELSE lft END
rgt = CASE
WHEN rgt BETWEEN droplft AND droprgt THEN rgt - 1
WHEN rgt > droprgt THEN rgt -2
ELSE rgt END;
WHERE lft > droplft;
END;
Листинг 1
CREATE TABLE Personnel
(emp CHAR(10) PRIMARY KEY,
salary DECIMAL(8,2) NOT NULL CHECK(salary > = 0.00),
lft INTEGER NOT NULL,
rgt INTEGER NOT NULL,
CHECK(lft < rgt));
INSERT INTO Personnel VALUES ('Albert', 1000.00, 1, 28);
INSERT INTO Personnel VALUES ('Bert', 900.00, 2, 5);
INSERT INTO Personnel VALUES ('Charles', 900.00, 6, 19);
INSERT INTO Personnel VALUES ('Diane', 900.00, 20, 27);
INSERT INTO Personnel VALUES ('Edward', 750.00, 3, 4);
INSERT INTO Personnel VALUES ('Fred', 800.00, 7, 16);
INSERT INTO Personnel VALUES ('George', 750.00, 17, 18);
INSERT INTO Personnel VALUES ('Heidi', 800.00, 21, 26);
INSERT INTO Personnel VALUES ('Igor', 500.00, 8, 9);
INSERT INTO Personnel VALUES ('Jim', 100.00, 10, 15);
INSERT INTO Personnel VALUES ('Kathy', 100.00, 22, 23);
INSERT INTO Personnel VALUES ('Larry', 100.00, 24, 25);
INSERT INTO Personnel VALUES ('Mary', 100.00, 11, 12);
INSERT INTO Personnel VALUES ('Ned', 100.00, 13, 14);
Рисунок 1.
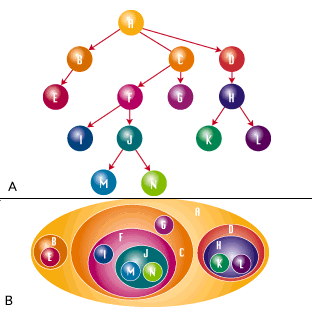
Дерево на представлено как A) граф и Б) вложенные множества.
Рисунок 2.

Удаление одиночного узла в середине дерева тяжелее чем удаление полных поддеревьев. Когда Вы удаляете узел в середине дерева, Вы должны решить, как заполнить отверстие. Имеются два пути. Первый метод к повышает одного из детей к позиции первоначального узла (предположим, что отец умирает, и самый старший сын занимает бизнес. Самый старший потомок всегда показывается как крайний левый дочерний узел под родителем.
Рисунок 3.
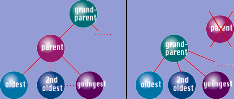
Второй метод для удаления одиночного узла в середине дерева состоит в том, чтобы подключить потомков к предку первоначального узла (можно сказать, что мамочка умирает, и дети приняты бабушкой).
© Joe Celko
DBMS Online - April 1996
Translated by SDM
Деревья в SQL. Часть 3.
Давайте продолжим наше обсуждение модели вложенных множеств для деревьев в SQL. Я не собираюсь рассматривать любую из моих предидущих статей и буду предполагать, что Вы все еще имеете копию таблицы Personnel, которую я использовал для примеров (DBMS, март 1996, страница 24). Если Вы не имеете прошлых выпусков, Вы можете осчастливить моего издателя, приобретя их.
Меня спрашивают, почему я не показываю больше процедурного кода в примерах. Прямо сейчас, ANSI и ISO пробуют договориться о стандартном процедурном языке для триггеров и хранимых процедур называемом SQL/PSM. Однако, этот стандарт еще не утвержден, что означает, что я должен использовать или свой собственный псевдо-код или выбирать одного производителя. Я решил использовать пока Английские комментарии, но я буду начинать использовать SQL/PSM, когда он будет завершен.
Наиболее хитрая часть обработки деревьев в SQL это нахождение способа конвертировать модель матрицы смежности в модель вложенных множеств в пределах структуры чистого SQL. Было бы довольно просто загрузить таблицу матрицы смежности в программу, и затем использовать рекурсивную программу преобразование дерева из учебника колледжа, чтобы построить модель вложенных множеств.
Честно говоря, такое преобразованиме дерева могло бы быть быстрее чем то, что я собираюсь показать Вам. Но я хочу сделать это в чистом SQL, чтобы доказать следующее: Вы можете делать на декларативном языке то же, что Вы можете делать на процедурном языке. Поскольку это обучающее упражнение, я буду объяснять с болезненной детальностью.
Классический подход к решению проблемы состоит в том, чтобы брать самое простой случай проблемы, и смотреть, можете ли Вы применять его к более сложным случаям. Если дерево не имеет узлов, то преобразование просто - ничего не делать. Если дерево имеет один узел, то преобразование простое - устанавливают левое значение в 1 и правое значение в 2. Природа матрицы смежности такова, что Вы можете двигаться только по одному уровню одновременно, так что давайте посмотрим на дерево с двумя уровнями - корень и непосредственные потомки. Таблица модели смежности напоминала бы следующее:
CREATE TABLE Personnel
(emp CHAR(10) NOT NULL PRIMARY KEY,
boss CHAR(10));
Personnel
emp boss
=================
'Albert' NULL
'Bert' 'Albert'
'Charles' 'Albert'
'Diane' 'Albert'
Давайте поместим модель вложенных множеств в ее собственную рабочую таблицу:
CREATE TABLE WorkingTree(
emp CHAR (10),
boss CHAR(10),
lft INTEGER NOT NULL DEFAULT 0,
rgt INTEGER NOT NULL DEFAULT 0);
Из предидущих абзацев этой статьи, Вы знаете, что корень дерева имеет левое значение 1, и что правое значение является удвоенным числом узлов в дереве. Пусть в рабочей таблице столбец boss будет всегда содержать ключевое значение корня первоначального дерева. В действительности, это будет имя вложенного множества:
INSERT INTO WorkingTree
--convert the root node
SELECT P0.boss, P0.boss, 1,
2 * (SELECT COUNT(*) + 1
FROM Personnel AS P1
WHERE P0.boss = P1.boss)
FROM Personnel AS P0;
Теперь, Вы должны добавить потомков в таблицу вложенных множеств. Первоначальный босс останется тот же самый. Порядок потомков - естественный порядок ключа; в данном случае emp char(10):
INSERT INTO WorkingTree
--convert the children
SELECT DISTINCT P0.emp, P0.boss,
2 * (SELECT COUNT(DISTINCT emp)
FROM Personnel AS P1
WHERE P1.emp < P0.emp
AND P0.boss IN (P1.emp, P1.boss)),
2 * (SELECT COUNT(DISTINCT emp)
FROM Personnel AS P1
WHERE P1.emp < P0.emp
AND P0.boss IN (P1.boss, P1.emp)) + 1
FROM Personnel AS P0;
Фактически, Вы можете использовать эту процедуру, чтобы конвертировать модель матрицы смежности в лес деревьев, каждое из которых - модель вложенных множеств, идентифицированная ее корневым значением. Таким образом, генеалогическое дерево Альберта - набор строк, которые имеют Альберта как предка, генеалогическое дерево Берта - набор строк, которые имеют Берта как предка, и так далее. (Эта концепция иллюстрирована в рисунках 1 и 2.
Поскольку первоначальная таблица матрицы смежности повторяет нелистовые узлы, некорневые узлы, в столбцах emp и boss, таблица WorkingTree дублирует узлы как корень в одном дереве и как потомок в другом. Запрос также будет странно себя вести со значением NULL в столбце boss первоначальной таблицы матрицы смежности, так что Вы будете должны очистить таблицу WorkingTree следующим запросом:
DELETE FROM WorkingTree
WHERE boss IS NULL OR emp IS NULL;
Чтобы заставить эти деревья сливаться в одно заключительное дерево, Вы нуждаетесь в способе прикрепить подчиненное дерево к его предку. На процедурном языке, Вы могли выполнить это программой, которая будет делать следующие шаги:
- Найти размер подчиненного дерева.
- Найти место, куда подчиненное дерево вставляется в дерево-предок.
- Раздвинуть дерево-предок в точке вставки.
- Вставить подчиненное дерево в точку вставки.
На непроцедурном языке, Вы исполнили бы эти шаги вместе, используя логику всех перечисленных пунктов. Вы начинаете этот процесс, задавая вопросы и отмечая факты:
Q)Как выбирать дерево-предок и его подчиненное дерево в лесу?
A)Ищем одиночное ключевое значение, которое является потомком в дерево-предке и корнем подчиненного дерева;
Q)Как определить на сколько необходимо раздвинуть дерево-предок?
A)Это размер подчиненного дерева, равный (2 * (select count(*) from Подчиненое)).
Q)Как определить точку вставки?
A)Это - строка в таблице предка, где значение emp равно значению boss в подчиненной таблице. Вы хотите поместить подчиненное дерево левее левого значения этого общего узла. Небольшие алгебраические вычисления дают Вам число, добавляемое ко всем левым и правым значениям справа от точки вставки.
Самый простой способ это объяснить- при помощи таблицы отношений, показанной в табл. 1.
ПРИМЕЧАНИЕ ПЕРЕВОДЧИКА: Я не знаю, что он имел в виду насчет самого простого способа объяснения, но ни черта не понял в этой таблице :)))) Если вам все понятно, то объясните мне, pls, письмом :)))
Вы готовы к написанию процедуры, объединяющей два дерева:
CREATE PROCEDURE TreeMerge(superior NOT NULL, subordinate NOT NULL)
BEGIN
DECLARE size INTEGER NOT NULL;
DECLARE insert_point INTEGER NOT NULL;
SET size = 2 * (SELECT COUNT(*)
FROM WorkingTree WHERE emp = subordinate);
SET insert_point = (
SELECT MIN(lft)
FROM WorkingTree
WHERE emp = subordinate AND boss = superior) - 1;
UPDATE WorkingTree
SET boss = CASE WHEN boss = subordinate
THEN CASE WHEN emp = subordinate
THEN NULL
ELSE superior END
ELSE boss END,
lft = CASE WHEN (boss = superior AND lft > size)
THEN lft + size
ELSE CASE WHEN boss = subordinate AND emp <> subordinate
THEN lft + insert_point
ELSE lft END
END,
rgt = CASE WHEN (boss = superior AND rgt > size)
THEN rgt + size
ELSE CASE WHEN boss = subordinate AND emp <> subordinate
THEN rgt + insert_point
ELSE rgt END
END
WHERE boss IN (superior, subordinate);
--Удаляем избыточные копии корня подчиненного дерева
DELETE FROM WorkingTree WHERE boss IS NULL OR emp IS NULL;
END;
Обнаружить пары внешних и подчиненных деревьев в таблице WorkingTree очень просто. Следующий запрос становится пустым, когда все боссы установлены в одно и тоже значение:
CREATE VIEW AllPairs (superior, subordinate)
AS
SELECT W1.boss, W1.emp
FROM WorkingTree AS W1
WHERE EXISTS( SELECT * FROM WorkingTree AS W2 WHERE W2.boss = W1.emp)
AND W1.boss <> W1.emp;
Но Вы хотели бы получить только одну пару, которую Вы передатите в только что разработанную процедуру. Чтобы переместить одну пару, берем крайнюю левую пару из прошлого запроса:
CREATE VIEW LeftmostPairs(superior, subordinate)
AS
SELECT DISTINCT superior,
(SELECT MIN(subordinate)
FROM AllPairs AS A2
WHERE A1.superior = A2.superior)
FROM AllPairs AS A1
WHERE superior = (SELECT MIN(superior) FROM AllPairs);
Теперь все, что Вам осталось сделать - поместить этот запрос в ранее разработанную процедуру - и у вас будет процедура, которая сольет вместе лес деревьев слева направо. Используя цикл WHILE, контролируюший наличие значений в LeftmostPairs делайте вызовы процедуры. Это единственная процедуральная структура во всей хранимой процедуре.
Таблица 1
| C1 | row in superior | y | y | y | y | n | y | n |
| C2 | row in subord | n | n | n | n | y | y | n |
| C3 | lft > cut | n | n | y | y | - | - | - |
| C4 | rgt > cut | n | y | n | y | - | - | - |
| A1 | Ошибка | | | 1 | | | 1 | |
| A2 | lft := lft + size | | | | 1 | | | |
| A3 | rgt := rgt + size | | 1 | | 2 | | | |
| A4 | lft := lft | 1 | 2 | | | | | 1 |
| A5 | rgt := rgt | 2 | | | | | | 2 |
| A6 | lft := lft + cut | | | | | 1 | | |
| A7 | rgt := rgt + cut | | | | | 2 | | |
|
