|
SQL - структурированный язык запросов, разработанный фирмой IBM для
своей системы управления базами данных DB/2, впоследствии ставший
общепризнанным стандартом. На этом языке строится практически все Ваше общение
с СУБД. С его помощью Вы создаете базы данных, создаете таблицы, наполняете их
данными, производите выборку данных, изменяете их, создаете backup'ы вашей
базы данных и много чего еще. Этот язык является стандартом "де-факто" в
современных системах управления базами данных. Эта статья предназначена в
первую очередь для тех, кто хотел бы узнать, что это за зверь такой и как с
его помощью работать со своей базой данных.
Небольшое вступление
про то, как работают современные СУБД. Взаимодействие пользователя и СУБД
осуществляется посредством технологии клиент-сервер. Где, как несложно
догадаться, СУБД есть сервер, а пользователь - клиент. При этом пользователей
(т.е. клиентов) может быть много, в зависимости от конфигурации СУБД и от
системных ресурсов машины. Связь между клиентом и сервером осуществляется по
протоколу транспортного уровня TCP (Transfer Control Protocol) из стека
протоколов TCP/IP. Соответственно связь устанавливается по определенному
tcp-порту. Он используется для установления логического соединения (которое
устанавливается только протоколом TCP и производными от него протоколами
пользовательского уровня: SMTP, Telnet, HTTP, Ftp и пр.). После соединения
пользователь проходит процесс аутентификации. После этого пользователь
посылает серверу СУБД SQL-запросы и получает на них ответы. Ответом может быть
либо ошибка, либо данные, либо подтверждение выполненной команды. Думаю,
технология наглядна и проста, поэтому можно идти далее.
Каким образом мы
можем связаться с сервером баз данных, чтобы начать передавать sql-запросы?
Это можно осуществить, по крайней мере, двумя способами, в зависимости от
того, что мы хотим делать. Если нам необходимо просто создать базу данных,
создать в ней таблицы и внести несколько записей, то все это можно сделать при
помощи программы-клиента. Она должна поставляться вместе с выбранной СУБД. В
mySQL это программа с именем mysql (или mysql.exe в оконной версии).
Посмотрите контекстную помощь, чтобы посмотреть параметры, с которыми она
вызывается. По умолчанию этот клиент будет пытаться соединиться к
loopback-адресу (127.0.0.1). Второй вариант - это когда нам надо написать
программу, которой надо делать выборку в базе данных, добавлять, удалять и
модифицировать записи непосредственно в скрипте (CGI, perl).
Для начала,
запустив mysql с необходимыми параметрами (или без таковых), установим
соединение с СУБД. Если не произошло никаких ошибок, то мы должны увидеть
приглашение для ввода команд или SQL-запросов. Для создания базы данных
введем:
CREATE DATABASE TEST1;
Таким образом, мы создали базу данных с
именем TEST1. Сразу надо упомянуть, что SQL не чувствителен к регистру,
поэтому мы могли бы записать и так:
create database test1;
Точка с
запятой в конце предложения принята во многих (но не во всех) SQL для
различных СУБД. Если брать эту команду в общем виде, то она выглядит следующим
образом:
CREATE DATABASE [IF NOT EXISTS] db_name
где db_name - имя базы
данных, которую мы собрались создавать.
Три слова в квадратных скобка
позволяют сперва проверить, не существует ли уже такая база данных, и если
нет, то только тогда создает ее.
В случае если мы пишем файл-скрипт,
состоящий из SQL-запросов, для создания начального (пустого) варианта нашей
базы данных, то перед тем как создать базу данных, мы удаляем уже созданную.
Это выполняется при помощи оператора DROP:
DROP DATABASE [IF EXISTS]
db_name
где db_name - имя удаляемой базы данных.
Конструкция IF EXISTS,
заключенная в квадратные скобки, позволяет перед удалением базы данных
проверить, существует ли она. Эта конструкция позволяет описывать логичные и
последовательные предложения на SQL и естественно избежать появления ошибки
при отсутствии удаляемой базы. Команда DROP удаляет физическим образом базу
данных с диска, удаляя файлы из директории базы данных со следующими
расширениями: .bak, .dat, .hsh, .isd, .ism, .mrg, .myd, .myi, .db,
.frm.
Теперь можно перейти к созданию таблиц в только что созданной нами
базе данных TEST1. Таблицы создаются при помощи конструкции CREATE
TABLE:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(описание_полей_таблицы)];
где tbl_name - собственно имя создаваемой
таблицы.
В различных СУБД присутствуют различные дополнительные параметры.
Мы не будем их рассматривать в этой статье. Эти параметры можно посмотреть в
документации, поставляемой с соответствующей СУБД.
Ключевое слово TEMPORARY
может быть использовано в случае, если нам необходимо временно создать
какую-либо таблицу, не сохраняя ее на диск. Т.е. эта временная таблица будет
существовать, пока связь с СУБД не будет разорвана. С конструкцией IF NOT
EXISTS, думаю, все понятно (по аналогии с предыдущими).
Отдельно рассмотрим
формат описания полей таблицы. Помимо простого определения имен полей и
сопоставления им типов, мы можем определять множество дополнительных
параметров. Их количество, опять же, зависит от используемой Вами СУБД. Среди
этих параметров могут быть следующие: определения поля автоматически
инкрементируемого поля (это значит, что при каждом добавлении записи в эту
таблицу значение поля, определенного как AUTO_INCREMENT, будет увеличено на
единицу в добавленной записи); определение значения поля, присваиваемого по
умолчанию; пометка поля как главного ключа для индексирования PRIMARY KEY;
установить проверку на уникальность значения поля во всех записях UNIQUE и
пр.
Поля описываются по следующему формату:
(col_name type
[дополнительные_параметры_поля], ...)
где col_name - имя поля,
type -
тип поля.
Существует очень много различных типов полей. Каждая группа
разработчиков СУБД вводит свои новые типы, без которых, по их мнению,
просто-таки не могут обойтись пользователи их продукта. И иногда эти типы
действительно очень удобны и полезны. Однако пользоваться ими я бы не
советовал. Основная проблема - несовместимость со стандартом ANSI SQL. Вот
типы полей, без которых обойтись практически невозможно:
INTEGER[(length)]
[UNSIGNED]
REAL[(length,decimals)]
[UNSIGNED]
CHAR(length)
TEXT
INTEGER - целочисленный тип. Length
определяет его длину в разрядах. Параметр UNSIGNED устанавливает тип этого
поля как целочисленный беззнаковый (модуль, если хотите :)).
REAL -
действительно число. Length - длина, а decimals - число знаков после запятой.
UNSIGNED, как и в INTEGER.
CHAR - символ/массив символов (строка). Длина
строки задается параметром length.
TEXT - это просто большой блок, куда
можно помещать большой объем данных (текст, к примеру).
Это малая часть
всех определенных типов. Без рассмотрения остались такие типы, как DATE, TIME,
DATETIME, SET(), ENUM(), различные вариации INTERGER и вещественных типов и
прочие. Насчет первых трех скажу, что гораздо эффективнее и удобнее для
времени и даты завести поле с типом, к примеру, CHAR(30). В это поле мы
записываем текущее значение Unix-времени. Для тех, кто не знает - Unix-время
отсчитывается с января 1970-го года посекундно. Т.е. оно представляет собой
длинное число, которое впоследствии можно преобразовать с точностью до
секунды. Но это лишь моя скромная точка зрения. Описание остальных типов можно
посмотреть в документации к Вашей СУБД.
Ну, а сейчас опишем и создадим
первую таблицу в базе данных TEST1:
CREATE TABLE IF NOT EXISTS myTbl1 (a1
INTEGER UNSIGNED, a2 CHAR(30), a3 REAL(4,3), a4 TEXT);
В результате, если
уже не существует таблицы с именем myTbl1, то она будет создана в соответствии
с определенными полями.
Рассуждение на тему именования полей и таблиц имеет
мало отношения непосредственно к SQL, поэтому особо останавливаться на теме
проектирования баз данных не стоит. Единственное, что нужно отметить, так это
то, что имя таблицы может непосредственно указывать, в какой базе данных ее
нужно создать. По умолчанию, это текущая выбранная база данных. В клиенте к
mySQL есть команда use db_name, которая и устанавливает текущую базу данных.
Если же Вы не уверены в том, что текущая база данных именно та, в которой Вы
хотели бы создать таблицу, то можно вместо myTbl1 написать TEST1.myTbl1.
Теперь ясно, что Вы ссылаетесь на базу данных с именем TEST1, и таблица будет
создана именно в ней.
Предположим, что Вы создали таблицу, наполнили ее
данными и вдруг обнаружили, что совсем забыли про одно немаловажное поле.
Можно не опасаться пересоздания всей таблицы. В ANSI SQL существует
специальный оператор для добавления новых полей в таблицу:
ALTER TABLE
tbl_name alter_specifications
где tbl_name - имя
таблицы,
alter_specifications - определение тех изменений в структуре
таблицы, которые необходимо провести.
Рассмотрим простой пример добавления
поля справа от всех полей таблицы:
ALTER TABLE TEST1.myTbl1 ADD (a5
INTEGER, a6 TEXT);
Если же мы хотим вставить эти два поля в самом начале
либо после какого-либо другого поля, то используем ключевые слова FIRST и
AFTER col_name:
ALTER TABLE TEST1.myTbl1 ADD (a5 INTEGER, a6 TEXT)
FIRST;
или
ALTER TABLE TEST1.myTbl1 ADD (a5 INTEGER, a6 TEXT) AFTER
a3;
Создав таблицу, можем приступить к ее наполнению. Добавление записей
осуществляется при помощи оператора INSERT:
INSERT [INTO] tbl_name
[(col_name,...)] VALUES (expression,...)
INTO используется только для
упрощения понимания целостного SQL-предложения. Вы, наверное, уже успели
заметить (особенно те, кто знает английский), что все строчки SQL очень легко
читаются и интуитивно понятны даже пользователю, который никогда с SQL не
работал.
Col_name заменяем на поля, которые мы хотим вставить в качестве
записи. Если Вы собираетесь заполнять все поля при добавлении записи, то можно
не задавать имена полей. По умолчанию будут все определенные в таблице поля. В
VALUES вместо expression, через запятую, указываем значения полей в
добавляемой записи.
Например:
INSERT INTO myTbl1 VALUES(1, 'Иванов
И.И..', 1500, 'Программист. Имел опыт работы ...');
INSERT INTO myTbl1
(a1,a2,a3) VALUES(1, 'Сидоров А.А.', 2500);
В первом случаем мы просто
заполняем все поля записи и добавляем ее в таблицу myTbl1. Во втором мы
заполняем только поля a1, a2 и a3, оставляя поле a4 не заполненным, и
добавляем полученную запись в таблицу.
Для работы с записями определено еще
несколько операций: удаление, изменение, замена и пр.
Операция DELETE
предназначена для удаления записей из таблицы базы данных. Формат этого
оператора следующий:
DELETE FROM tbl_name [WHERE условие];
Т.е., так как
в понятии SQL записи любой таблицы не имеют своих порядковых номеров и
располагаются не по порядку, то для того, чтобы удалить какую-то конкретную
запись, следует использовать условие, например:
DELETE FROM myTbl1 WHERE
a1=1;
В результате все записи, у которых поле a1 установлено в 1, будут
удалены. Для удаления же всех записей таблицы мы можем поставить любое
условие, которое всегда верно:
DELETE FROM myTbl1 WHERE 3>2;
Таким
образом, все записи таблицы myTbl1 будут удалены.
Специально для изменения
записей таблицы в SQL был введен дополнительный оператор UPDATE. Формат его
использования таков:
UPDATE tbl_name SET (поле=значение) WHERE
(условие);
Этот оператор позволяет вносить изменения в уже существующие
записи. Рассмотрим пример использования:
UPDATE myTbl1 SET (a2 = 'Это
второй элемент!', a3 = 2.5) WHERE (a1 = 1);
Этой строчкой мы устанавливаем
значение полей a2 и a3 во всех записях таблицы myTbl1, у которых поле a1
содержит 1.
Выше были вкратце разобраны основные операторы для создания и
наполнения базы данных. Само собой разумеется, что функциональные возможности
SQL не ограничиваются этими операторами. Даже из названия (Язык
Структурированных Запросов) следует, что первое и основное его предназначение
- это выборка из базы данных.
Язык SQL предоставляет пользователю мощный
интерфейс с базой данных. Любая, сколь угодно сложная, выборка данных может
быть описана посредством SQL-запроса. Понятие реляционных баз данных
подразумевает объединение таблиц в некую иерархию связанных между собой
объектов. Объектом в данном случае является обычная таблица. Связи между
таблицами (объектами) осуществляются по ключевым полям. В SQL нет какого-либо
средства для организации непосредственной связи таблиц. Эта связь
устанавливается уже в самих SQL-запросах, при помощи логических
операций.
Рассмотрим простейший обособленный случай. Имеем две таблицы.
Первая содержит служебные данные о сотрудниках какой-либо фирмы, а вторая -
личную информацию о них же:
CREATE TABLE tblFirst (a1 CHAR(10), a2 INTEGER,
a3 DATE, a4 TEXT);
a1 - идентификатор пользователя, a2 - средняя заработная
плата, a3 - дата поступления на работу, a4 - замечания;
CREATE TABLE
tblSecond (a1 CHAR(10), a2 CHAR(70), a3 DATE, a4 TEXT);
a1 - идентификатор
пользователя, a2 - ФИО, a3 - дата рождения, a4 - характеристика и другие
биографические сведения.
Имена полей в этих таблицах специально были взяты
с одинаковыми именами, чтобы в дальнейшем рассмотреть, как задавать
альтернативное имя поля.
Думаю, Вы уже догадались, что логическая связь
между этими двумя таблицами устанавливается посредством идентификационного
поля a1. Как уже говорилось выше, SQL не нуждается в определении связи между
таблицами.
Думаю не ошибусь, если скажу, что самым распространенным
оператором в SQL является SELECT. Именно с его помощью Вы и сможете получать
нужную вам информацию. Довольно проблематично сформировать формат SELECT в
общем виде, учитывая вложенные запросы и прочее, поэтому я думаю, что можно
начать напрямую с примеров.
Предположим, Вам нужно выбрать все значения
идентификаторов и заработных плат из таблицы tblFirst. Запрос, выполняющий эту
выборку, выглядит так:
SELECT a1, a2 FROM tblFirst;
Несложно заметить,
что после оператора SELECT идут имена полей, которые следует выбирать, а после
FROM - имя таблицы, откуда выбирать. Результатом запроса явится таблица,
состоящая из двух столбцов a1 и a2, выбранных значений этих полей из всех
записей таблицы tblFirst.

И вот результативная таблица:

Этот пример иллюстрирует
обычную безусловную выборку полей всех записей таблицы. Теперь давайте
попробуем наложить условие. К примеру, выберем всех сотрудников, у которых
заработная плата выше 60000 рублей и дата поступления на работу не превышает
01/01/2001 года:
SELECT * FROM tblFirst WHERE (a2 > 60000) and (a3 <
'01/01/2001');
Получим таблицу:
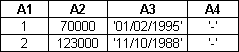
Условие в операторе WHERE определяется точно так же,
как и в UPDATE. Символ "*" в нашем запросе позволяет выбирать все поля
таблицы, не определяя их через запятую. Эта замена иногда оказывается весьма
кстати. В результирующей таблице мы увидели, что заданному условию
соответствует лишь две записи из трех. В определенном нами условии
используются два логических выражения, соединенных оператором
AND.
Если перед SELECT указать ключевое слово DISTINC, то при
формировании результирующей таблицы дубликаты записей не будут отображаться
(т.е. это фактически означает выбор уникальных записей).
С обычной выборкой
данных все понятно. Но остается один вопрос: как все-таки связать две таблицы,
чтоб при запросе получить данные из обеих? Например, вывести список фамилий и
дат рождения тех сотрудников, которые поступили на работу не позже
'01/01/1990' года в порядке возрастания средней заработной платы:
SELECT
tblSecond.a2, tblSecond.a3 FROM tblFirst, tblSecond WHERE (tblFirst.a1 =
tblSecond.a1) and (tblFirst.a3 > '01/01/1990') ORDER BY tblFirst.a2;
В
этом запросе используется способ прямой адресации к полю какой-либо таблицы.
Как видно из примера, для того чтобы обратиться к полю a2 таблицы tblSecond,
мы записываем вместо a2, tblSecond.a2. В этом случае SQL понимает, что поле a2
- это поле, принадлежащее таблице tblSecond. Для того чтобы в запросе мы могли
ссылаться на данные двух таблиц, независимо от того, какие и чьи поля мы
отбираем после SELECT, после слова FROM должны перечисляться все используемые
в запросе таблицы. В нашем случае это tblFirst и tbl Second. Ну и наконец для
сортировки используем конструкцию "ORDER BY field_name". Она означает, что в
результирующей таблице все записи будут отсортированы по возрастанию в поле
field_name. Для того чтобы сортировать по убыванию, в конце ORDER BY
необходимо добавить ключевое слово DISC: "ORDER BY field_name DISC".
Ну, и
напоследок следует рассмотреть еще несколько немаловажных (если не сказать
просто незаменимых) моментов при выборке данных.
Иногда очень полезным
бывает использование вычисляемых значений полей. SQL позволяет выбирать не
только просто поля, но и предварительно проводить с ними какие-то
арифметические действия. Вот, например:
SELECT MAX(a1), (a2*a2)+5 FROM
tblFirst;
С помощью конструкции BETWEEN ... AND ... можно отобрать строки,
в которых значения какого-либо поля находятся в заданном диапазоне.
Например:
SELECT * FROM tblFirst WHERE a3 BETWEEN '01/01/00' AND
'01/01/02';
Если необходимо проверить, входит ли какое-либо значение поля в
множество, то можно использовать оператор IN:
SELECT * FROM tblFirst WHERE
a1 IN ('2','3','4');
Можно также задать NOT IN - при этом условие будет
выполняться тогда, когда a1 не входит в множество ('2','3','4'). Этот оператор
удобно использовать совместно с вложенными запросами:
SELECT * FROM
tblFirst WHERE a1 IN (SELECT a1 FROM tblSecond);
Сначала отработает запрос
в скобках, результат работы которого представляет собой массив значений поля
a1 записей таблицы tblSecond. И соответственно будет идти проверка, входит ли
в это множество значение a1 таблицы tblFirst.
И, наконец, оператор LIKE
позволяет задавать шаблоны в условиях. Для определения этих самых шаблонов
используются специальные символы:
"_" - обозначает любой одиночный
символ;
"%" - задает любую последовательность из N символов (причем N может
быть 0);
Пример использования:
SELECT * FROM tblSecond WHERE a2 LIKE
'Иванов%';
Будут отобраны все записи из таблицы tblSecond, где поле a2
вначале содержит 'Иванов'.
С помощью комбинации этих условных операторов
можно создавать сложные и эффективные запросы. Естественно, что здесь
рассмотрены не все в языке SQL. Да и я не задавался такой целью. Однако все
самое необходимое на первое время рассмотрено все же было. И, я думаю, этого
достаточно для того, чтобы приступить хотя бы к более углубленному изучению
SQL.
Литература по SQL
|
