
В предлагаемой статье кратко описаны особенности хранения и поиска текстовых данных в базах SQL Server 2000. Она адресована администраторам и разработчикам, которые планируют реализовать такой тип хранения.
Варианты хранения и загрузка текста в таблицы
Для начала стоит вспомнить форму хранения текстовой информации в базе данных. Текстовая информация может храниться в таблицах базы данных SQL Server 2000 в двух вариантах. В первом варианте тексты представляют собой значения полей типа char, varchar, nchar, nvarchar, text, ntext. Второй вариант хранения текстов предполагает, что они являются содержимым поля типа image, в которое загружаются в формате документов MS Office или других приложений. В этом случае в таблице в дополнительном поле должно храниться расширение файла, соответствующее типу документа. Хранение расширения файла позволяет подключать соответствующие фильтры при обработке или отображении содержимого поля.
Если тексты хранятся в формате приложений, в которых они созданы, то изначально они существуют в виде файлов. Для загрузки файлов в таблицы можно использовать утилиту TextCopy, которая находится в папке \Program Files\Microsoft SQL Server\MSSQL\Binn. Данная утилита предназначена для обновления (Update) поля типа text и image и заполнения его содержимым заданного файла, а также для выгрузки содержимого полей данного типа в файл.
Синтаксис утилиты следующий:
TEXTCOPY [/S [sqlserver]] [/U [login]] [/P
[password]]
[/D [database]] [/T table] [/C column]
[/W"where clause"]
[/F file] [{/I | /O}] [/K chunksize] [/Z] [/?]
До вызова утилиты нужно заполнить в таблице поле, содержимое которого будет обновляться утилитой. Утилиту TextCopy можно вызывать в командном файле несколько раз, а выполнение командного файла назначено в виде шага задачи.
После ключа /W нужно обязательно написать слово where. Например, для обновления из файла c:\Docs\AcademicLicense.doc поля DocField записи со значением поля DocID = 2 таблицы MyTable базы Mydb сервера MyServer вызов TextCopy имеет следующий вид:
TextCopy /S MyServer /u sa /P /D Mydb /T MyTable /C DocField /W "Where DocID = 2" /F "с:\Docs\AcademicLicense.doc" /I /Z
Ключ /I соответствует импорту в таблицу, а /Z выводит отладочную информацию.
Безусловно, у разработчиков всегда есть возможность, не прибегать к помощи утилиты TextCopy, а написать свою программу для считывания информации из файлов.
Полнотекстовый индекс и полнотекстовый каталог
Независимо от варианта хранения текста, в SQL Server можно воспользоваться функцией полнотекстового, т. е. лингвистического, поиска. Концепция полнотекстового поиска в SQL Server основана на использовании Microsoft Search. Служба Micro-soft Search выполняет две основные функции: индексирование и поиск.
Для обеспечения полнотекстового поиска сначала необходимо создать полнотекстовый индекс. Этот всегда единственный индекс для таблицы, но в него может входить несколько полей. Полнотекстовый индекс не может быть построен для представлений, временных или системных таблиц, а только для постоянных пользовательских таблиц. Полнотекстовый индекс учитывает значащие слова в соответствующем поле. Его структура обеспечивает эффективный лингвистический поиск слов и фраз. Для построения полнотекстового индекса в таблице должно присутствовать уникальное поле. Уникальность поля обеспечивается первичным ключом. При построении полнотекстового индекса используются эти ключевые значения и содержимое полей с текстом. Размер ключа влияет на размер индекса и на работу с ним. В документации приведено ограничение на длину ключа, она не должна превышать 450 байт. Если длина ключа достигла 100 байт, предлагается поменять ключ.
Полнотекстовые индексы хранятся в виде специальных файлов в отдельном каталоге файловой системы, называемом полнотекстовым каталогом. В каталоге могут храниться полнотекстовые индексы для нескольких таблиц. Это каталог файловой системы, доступный администратору и службе Microsoft Search. Администратору следует помнить о том, что полнотекстовый каталог занимает довольно много места. Размер его может превышать размер текстовой информации, для работы с которой он создавался, если информации мало. Служебные файлы и папки в полнотекстовом каталоге имеют объем от 4 Мбайт. Полнотекстовые каталоги на сервере нумеруются от 1 до 256, и информация о них хранится в системной таблице sysfulltextcatalogs. Дополнительно в таблице sysindexes в поле ftcatid для таблицы хранится номер ее полнотекстового каталога. Каждая ли таблица должна иметь свой полнотекстовый каталог? Официальный ответ в документации звучит так: если таблица содержит или будет содержать миллион записей, тогда ей необходим отдельный полнотекстовый каталог. В остальных случаях количество полнотекстовых каталогов и их распределение между таблицами определяется характером работы с таблицами и режимом обновления каталога. Обновляемые таблицы часто имеют общий полнотекстовый каталог для упрощения сопровождения, но использование общего каталога может снизить скорость выполнения запросов. Использование отдельных каталогов для таблиц ограничено числом 256 для сервера в целом.
При резервном копировании базы полнотекстовый индекс не помещается в резервную копию, но при копировании базы на другой сервер он может быть создан заново.
Индексация текстов, хранимых в поле типа image
Принципиальным новшеством SQL Server 2000 является фильтрация, которая позволяет индексировать и опрашивать документы, хранящиеся в поле типа image. Объем файла, который хранится в таком поле, не должен превышать 16 Мбайт, а объем отфильтрованного текста - 256 Кбайт. Тип документа задается в отдельном поле таблицы как файловое расширение, которое имел бы документ при хранении в файловой системе. Мастер полнотекстового поиска (Full-Text Indexing Wizard) требует указать поле привязки (Binding column), в котором хранятся типы документов.
Аналогичный параметр должен быть задан и при использовании системной хранимой процедуры sp_fulltext_column. Для каждого документа SQL Server 2000 выбирает соответствующий фильтр, исходя из расширения файла, указанного в поле привязки. Если в поле привязки ничего не задано, то SQL Server 2000 считает документ текстовым с расширением txt.
Фильтр в зависимости от его реализации может поддерживать объекты, встроенные в родительский объект, но не отслеживает связи с другими объектами. На Экране 1 показано, как задать индексируемое поле и поле привязки.
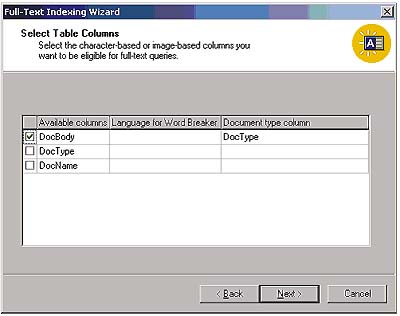 |
| Экран 1. Индексирование поля типа image. |
Этапы создания полнотекстового индекса
Полнотекстовый индекс строится в несколько этапов. Если тексты хранятся в поле типа image, то они сначала фильтруются по типу документа. Фильтр представляет собой динамическую библиотеку, которая извлекает из документа его содержимое в виде потока текста. Нужный фильтр определяется по расширению документа, хранящемуся в отдельном поле. Механизм полнотекстового поиска загружает соответствующий фильтр документа, и тот выбирает текстовую информацию для индексирования. В SQL Server 2000 реализованы фильтры для следующих типов документов: doc, xls, ppt, txt, htm. На сайте MSDN.
Microsoft.com можно найти средства написания и подключения новых фильтров для файлов других типов. В случае хранения текстов не в полях типа image фильтрация упрощается, так как фильтр известен заранее.
На следующем этапе поток текста должен быть разбит на слова с помощью специального делителя (Word Breaker). Разбиение на слова зависит от локализации, т. е. используемого языка. В Microsoft Search применяется несколько встроенных библиотек локализации. Встроенные библиотеки существуют для следующих языков: китайского, английского, французского, немецкого, итальянского, японского, корейского, испанского, шведского.
Они обеспечивают разбор соответствующих языку грамматических конструкций. Для всех прочих языков применяется нейтральный (Neutral) делитель, который в качестве разделителя слов использует пробелы. Язык для хранения данных в полнотекстовом индексе определяется параметром Unicode collation locale, выбираемым во время установки SQL Server 2000. Третий этап заключается в отбрасывании незначащих слов (Noise words), или стоп-слов, к которым относятся междометия, союзы, предлоги.
Списки незначащих слов хранятся в \Program Files\Microsoft SQL Server\ MSSQL\FTDATA\Config под именами Noise. Расширение файла соответствует названию языка. Списки можно редактировать как обычные текстовые файлы. Имя папки файловой системы, содержащей полнотекстовый каталог, соответствует уникальному идентификатору полнотекстового каталога. Путь к каталогу можно найти в таблице sysfulltextcatalogs. Структура папок в полнотекстовом каталоге имеет стандартный вид (см. Экран 2). Для временных файлов используется папка С:\WINNT\TEMP\gthrsvc.
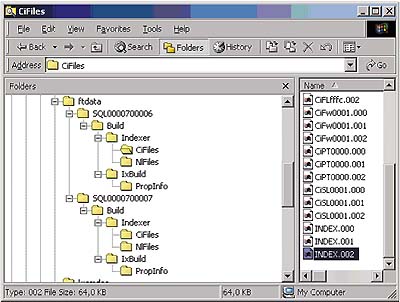 |
| Экран 2. Структура полнотекстового каталога. |
Сопровождение полнотекстового индекса
Сопровождение полнотекстовых индексов доставляет администратору дополнительные хлопоты. Можно выделить три основные задачи: резервное копирование полнотекстового каталога, обновление полнотекстового индекса и настройка сервера для оптимального выполнения полнотекстовых запросов.
Регулярное резервное копирование полнотекстового каталога можно обеспечить запуском программы NTBackup на шаге задания в SQL Server 2000. Предварительный или дополнительный шаг задания может служить для обновления индекса по расписанию или проверки его состояния. Для использования результата выполнения задания можно задействовать механизм оповещений SQL Server 2000.
Режимом обновления полнотекстового индекса можно управлять. Полнотекстовый индекс вначале строится по всем записям (Full population). Если в таблице есть поле типа timestamp, то можно использовать режим инкрементного обновления (Incre-mental population). В этом случае службе Microsoft Search передаются для обновления ключи и тексты только тех записей, для которых значение поля типа timestamp больше аналогичного параметра для полнотекстового индекса. При изменении структуры таблицы или структуры индекса при попытке выполнить инкрементное обновление всегда выполняется полное обновление. SQL Server может по требованию отслеживать изменения (Change Tracking) информации, используемой в полнотекстовом индексе. Если для полнотекстового индекса выбран режим отслеживания изменений, то в системной таблице Sysfulltextnotify сохраняется информация об удалении и добавлении записей, а также изменении полей, входящих в полнотекстовый индекс. Полнотекстовый индекс может быть приведен в соответствие этим изменениям вручную, по расписанию или в фоновом режиме. Расписание обновления может совпадать с расписанием резервного копирования полнотекстового каталога. Обновление в фоновом режиме обеспечивает обновление индекса сразу после внесения изменений в таблицу.
Службу полнотекстового поиска можно настроить на соответствующий уровень использования ресурсов. Для этого существует хранимая процедура sp_fulltext_service. Параметр resource_usage этой хранимой процедуры может принимать значения от 1, что соответствует фоновому режиму и минимальному использованию ресурсов, до 5, что соответствует выделению максимальных ресурсов. По умолчанию значение этого параметра устанавливается равным 3. Это средний уровень использования ресурсов.
Параметр connect_timeout позволяет задавать временной интервал в секундах, в течение которого служба Microsoft Search будет ожидать соединения с SQL Server 2000 для наполнения полнотекстового индекса. В SQL Server 2000 c Service Pack1 значение этого параметра по умолчанию устанавливается равным 120. Если сервер сильно загружен, значение можно увеличить. Например,
exec sp_fulltext_service 'Connect_Timeout', 190
Параметр data_timeout соответствует времени ожидания выдачи данных сервером для построения полнотекстового индекса. По умолчанию значение этого параметра равно 120.
Хранимую процедуру sp_fulltext_service можно использовать для удаления из файловой системы всех полнотекстовых каталогов, на которые нет ссылок в таблице sysfulltextcatalogs. Такое может случиться, если база или каталог были удалены при остановленной службе Microsoft Search.
exec sp_fulltext_service 'clean_up'
Команда Cleanup Catalogs из контекстного меню службы Full-Text Search в Enterprise Manager дает аналогичный результат.
Для эффективной работы полнотекстового поиска этой службе должен быть выделен достаточный объем оперативной памяти. Параметр конфигурации сервера max server memory нужно установить таким образом, чтобы оставшаяся виртуальная память для полнотекстового поиска была в полтора раза больше физической памяти.
При сопровождении полнотекстовых индексов нас может интересовать как состояние индексов, так и работа службы Microsoft Search. Справка по индексам может быть получена с помощью хранимых процедур sp_help_fulltext_tables и sp_help_fulltext_co-lumns, возвращающих информацию о таблицах и полях, для которых есть полнотекстовый индекс. Тот, кто привык работать с курсорами, может использовать курсорные варианты справочных процедур: sp_help_fulltext_tab-les_cursor, sp_help_fulltext_columns_cursor. Вызывая встроенные функции ObjectProperty и ColumnProperty, можно проверять наличие и задавать режим обновления полнотекстового индекса.
Например, для таблицы MyTable можно узнать:
- есть ли полнотекстовый индекс в таблице
SELECT
OBJECTPROPERTY(OBJECT_ID('MyTable'),
'TableHasActiveFulltextIndex');
- какой статус у индекса
SELECT
OBJECTPROPERTY(OBJECT_ID('MyTable'),
'TableFullTextPopulateStatus');
- работает ли отслеживание изменений
SELECT
OBJECTPROPERTY(OBJECT_ID('MyTable'),
'TableFullTextChangeTrackingOn');
- обновляется ли индекс в фоновом режиме
SELECT
OBJECTPROPERTY(OBJECT_ID('MyTable')
'TableFullTextBackgroundUpdateIndexOn');
- идентификатор индексируемого поля
SELECT
OBJECTPROPERTY(OBJECT_ID('MyTable'),
'TableFulltextKeyColumn');
- идентификатор полнотекстового каталога
SELECT OBJECTPROPERTY(OBJECT_ID('MyTable'), 'TableFulltextCatalogId'),
Для поля таблицы можно проверить наличие полнотекстового индекса:
SELECT COLUMNPROPERTY
-(OBJECT_ID('MyTable'), 'DocBody'
'IsFulltextIndexed' )
Справку о состоянии и параметрах службы Microsoft Search можно получить с помощью функции Fulltext-ServiceProperty. Например,
SELECT FulltextServiceProperty
('ResourceUsage')
SELECT FulltextServiceProperty
('ConnectTimeout')
SELECT FulltextServiceProperty
('DataTimeout')
Можно воспользоваться функцией FulltextCatalogProperty для определения состояния полнотекстового каталога. Например, для каталога Mycatalog можно узнать:
- статус каталога
SELECT FulltextCatalogProperty
('Mycatalog ', 'PopulateStatus');
- количество проиндексированных единиц
SELECT FulltextCatalogProperty
('Mycatalog ', 'ItemCount');
- размер индекса в мегабайтах
SELECT FulltextCatalogProperty
('Mycatalog ', ' IndexSize');
- количество ключевых значений, примерно равное количеству значащих слов
SELECT FulltextCatalogProperty
('Mycatalog ', 'UniqueKeyCount');
- время в секундах от 01.01.90 до последнего обновления каталога
SELECT FulltextCatalogProperty
(' mycatalog ', 'PopulateCompletionAge').
Работа с хранящимися в базе русскоязычными текстами
Приложения, работающие с текстами на русском языке, должны предоставить пользователю, говорящему и думающему по-русски, максимум возможностей в привычной для него языковой среде. Это предполагает выполнение сложных полнотекстовых запросов с поиском словоформ и вводом текста в свободном формате. Стандартная установка SQL Server обладает ограниченной лингвистической поддержкой русского языка. Для работы с текстами на русском языке используется нейтральный делитель, который считает значащими словами последовательности символов, разделенные пробелами. Это существенно увеличивает объем индекса. Хотя никаких сообщений об ошибках при выполнении запросов, содержащих FORMSOF или FREETEXT, сервер не выдаст, он будет возвращать только результат, соответствующий вхождению заданных слов, но не их словоформ. Для обеспечения работы FORMSOF и FREETEXT с русским языком необходимо использовать специальные решения. Подобные решения могут добавлять возможность полнотекстового поиска на русском языке непосредственно к поисковой машине Microsoft Search. Например, на этом уровне добавляет поддержку русского языка продукт ALESTA Search. На Рисунке 1 приведена архитектура полнотекстового поиска для такого случая. В других вариантах возможно использование отдельной поисковой машины.
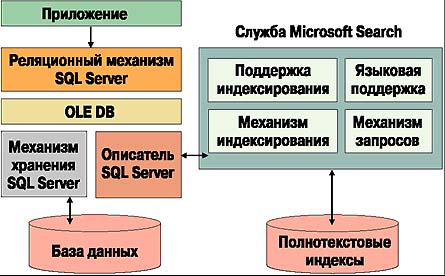 |
| Рисунок 1. Архитектура полнотекстового поиска. |
А теперь представим, что у нас есть таблица MyTable, в которой в поле Text Data, имеющем соответствующий тип данных, хранится проиндексированная информация. Информация представлена на русском и английском языке. Основная функция для полнотекстового поиска - CONTAINS. Проанализируем разные способы ее применения.
Простейший вариант ищет вхождение слова или фразы.
Например,
select * from MyTable where Contains (TextData, '"продукт"')
Этот запрос будет работать одинаково и в стандартном варианте, и при дополнительной поддержке русского языка.
SQL Server 2000 позволяет выполнять также полнотекстовый поиск по условию близкого расположения слов. Например,
select * from MyTable where Contains (TextData, '"лицензия" NEAR "BackOffice"')
Этот запрос будет искать все документы, в которых слова 'лицензия' и BackOffice находятся поблизости друг от друга. Расстояние между заданными словами измеряется тоже в словах с учетом принадлежности одному предложению или параграфу.
В стандартном варианте выполнение такого запроса возможно только при использовании нейтрального делителя, для которого русские и английские слова равнозначны.
Функция ISABOUT позволяет задавать относительные весовые коэффициенты значимости слов или выражений в диапазоне от 0.0 до 1.0.
Например,
select * from MyTable where Contains
(TextData, 'ISABOUT ("лицензия"
weight(0.8), "право" weight (0.1))')
В этом запросе нас больше интересует вхождение слова 'лицензия', ему назначен больший вес. Запрос будет выполнен одинаково как в стандартной версии, так и при дополнительной поддержке русского языка.
Для поиска словоформ в запросе нужно указать функцию FORMSOF. Первый параметр этой функции определает лингвистический принцип генерации словоформ. Он может иметь только одно значение, INFLECTIONAL, и подразумевает единственное и множественное число и глагольные формы.
Например,
select * from MyTable where Contains (TextData, 'FORMSOF (INFLECTIONAL, "программа" )') select * from MyTable where Contains (TextData, 'FORMSOF (INFLECTIONAL, "академическая" )') select * from MyTable where Contains (TextData, 'FORMSOF (INFLECTIONAL, "go")')
Из этих примеров первые два будут выполнены правильно только при установке дополнительной поддержки русского языка.
Частным случаем функции CONTAINS с комбинацией FORMSOF и ISABOUT можно считать функцию FREETEXT, которая позволяет задавать вопросы в свободной форме. Эта функция менее точная, чем CONTAINS. При обработке подобного запроса фраза, являющаяся аргументом FREETEXT, разбивается на слова, словам назначаются эвристические веса, от слов генерируются производные, после чего выполняется поиск всех комбинаций. Эту операцию выполняет зависящий от языка модуль варьирования лексической формы слова (stemming) или дифференциатор, генерирующий производные слова от исходной основной формы. Для стандартно поддерживаемых языков строятся также группы существительных (Noun Phrases). Из слов и групп формируются запросы, которым присваивается вес для вычисления рейтинга.
Например,
select * from MyTable where Freetext (TextData, '"Пользователи получают право использовать указанные программы"') select * from MyTable where Freetext (TextData, '"Принятие решения о количестве лицензий на BackOffice"') select * from MyTable where Freetext (TextData, '"Права пользователя"')
Эти запросы дадут полный и правильный результат только после установки поддержки русского языка.
Все приведенные рассуждения справедливы и при использовании функций CONTAINSTABLE и FREETEXTTABLE.
В заключение остается только предложить опробовать описанные возможности и функции на практике.