|
Игорь Попов
Сегодня вряд ли кому-нибудь из тех, кто связан с
разработкой программного обеспечения, нужно объяснять, что такое
объектно-ориентированное программирование и в чем его преимущества. Хотя бы
потому, что другого программирования практически не осталось. Основываясь на
простых и наглядных принципах, ООП, в сочетании с компонентным подходом и
распределенными вычислениями, успешно преодолевает любые барьеры на пути
повышения сложности программных систем. Однако, опыт работы над большими
проектами привел меня к мысли о том, что, возможно, в самих основах ООП имеются
некоторые пробелы и неопределенности, которые начинают проявляться при
достижении системой достаточно большого уровня сложности.
Здесь я буду пользоваться англоязычным термином
консистентность (consistency), поскольку соответствующий русскоязычный
термин непротиворечивость представляется мне несколько громоздким.
Консистентность, в данном случае, означает
соответствие значений всех переменных объекта его состоянию. Например,
объект-строка имеет две переменные: указатель блока памяти и длину строки.
Присваивая объекту более длинную строку, мы должны освободить старый блок
памяти, выделить новый, скопировать строку, изменить значение указателя и
значение длины. Перед выполнением первой из этих операций, данные объекта
консистентны, после выполнения последней - тоже. Между первой и последней
операциями, консистентность нарушена.
Когда мы вызываем какой - либо public метод
объекта, мы вправе ожидать, что данные объекта консистентны. Отсюда следует
первое правило:
Правило 1: При возврате из любого public
метода, данные объекта должны быть консистентны.
Несоблюдение этого правила является признаком
очень плохого стиля программирования, и не может быть оправдано ничем.
Большинство программистов интуитивно следуют этому правилу, однако, нарушители
не столь редки, особенно среди тех, кто только осваивает ООП.
Представим себе теперь достаточно сложную
объектную систему. Допустим, в данный момент выполняется некоторый метод объекта
A. В процессе выполнения, он вызывает метод объекта B. Согласно принципу
инкапсуляции - одному из базовых принципов ООП, мы не можем ничего предполагать
относительно того, каким образом реализован вызываемый метод. В частности, он
может, прямо или косвенно, вызвать какой-нибудь метод объекта A и изменить
состояние последнего. В результате, после возврата из вызова, состояние объекта
A может быть другим.
Даже если вы имеете дело с программой на C++,
код объекта B вам доступен, и вы можете убедиться в отсутствии рекурсивного
вызова, нет никакой гарантии, что, в дальнейшем, вы или другой программист, не
измените код так, что возникнет рекурсия. Принцип инкапсуляции нужно соблюдать
всегда, если не хотите нарваться на неприятности.
Таким образом, при обращении к любому
внешнему объекту мы не можем быть уверены в отсутствии рекурсивного вызова.
Это очень важный вывод. Из него следуют два правила, которые нужно соблюдать
программисту, чтобы гарантировать правильное функционирование системы:
Правило 2: Перед выполнением исходящего
вызова следует обеспечить консистентность данных объекта.
Правило 3: Необходимо учитывать, что, за
время исходящего вызова, состояние объекта может быть изменено.
В отличие от Правила 1, эти два правила не столь
интуитивны, и практически не упоминаются в литературе по
объектно-ориентированному программированию. Программисты редко их учитывают, что
способствует появлению странных, малопонятных и трудноуловимых ошибок.
Вероятность их возникновения возрастает с повышением сложности системы.
Возможно, на заре объектно-ориентированного программирования, когда связи между
объектами были простыми и обозримыми, эти правила не имели большого значения.
Современные системы достигают уже таких размеров, что отследить все
хитросплетение связей между компонентами становится нереальной задачей, и
соблюдение правил 2 и 3 становится жизненно необходимым. Лучший способ научиться
соблюдать правило - это привыкнуть к нему. Поэтому, я рекомендую всегда
соблюдать их, даже если ваша программа состоит всего из трех объектов.
Перейдем теперь к рассмотрению многопоточных
(multithreaded) систем. Один поток выполняет метод, изменяющий состояние
объекта. При этом, консистентность данных объекта может быть, временно,
нарушена. Если другой поток в это время будет выполнять какой-либо из методов
того же объекта, он будет иметь дело с неконсистентными данными. Во избежание
этого, в многопоточных системах обычно применяется блокировка, обеспечивающая, в
каждый момент времени, исполнение кода определенного объекта только одним
потоком. В простейшем случае, можно снабдить каждый объект мьютексом (mutex) или
критической секцией, которая захватывается потоком при входе в любой метод, и
освобождается перед возвратом из него [1]. Сделав
это, программист обычно считает, что консистентность данных объекта
гарантирована. Однако, мьютекс блокирует доступ к объекту только со стороны
'чужих' потоков. Если мы не будем соблюдать правила 2 и 3, 'свой' поток может,
во время рекурсивного вызова, нарушить работу системы ничуть не хуже 'чужого'.
Таким образом, использование классических средств синхронизации, основанных на
понятии потока - владельца защищаемого объекта, еще не гарантирует
консистентности. Правила 2 и 3 нужно соблюдать и в многопоточных системах.
Рассмотрим теперь распределенную объектную
систему на основе, например, CORBA или DCOM. Некоторый объект A получает вызов.
Во время его выполнения, он обращается к объекту B, находящемуся на другом
компьютере. Поток, который выполняет код объекта A переводится в состояние
ожидания до поступления ответа от объекта B. Во время этого ожидания, объект A
получает вызов от другого потока. При использовании типичного метода
синхронизации, описанного выше, этот вызов будет блокирован мьютексом до
завершения первого вызова, которое может произойти через значительное время,
после того, как по сети прийдет ответ от объекта B. В результате, оба потока
перейдут в состояние ожидания и система будет простаивать.
Однако, падение производительности - еще не
самое плохое, что может произойти. Если объекты одновременно вызовут друг друга,
может возникнуть тупиковая ситуация - дидлок (deadlock), как показано на Рис.
1.
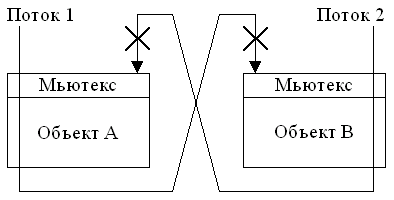
Рисунок 1. Дидлок при взаимном
вызове
Также, дидлок возникает, если происходит
рекурсия через удаленный вызов, как показано на Рис. 2.
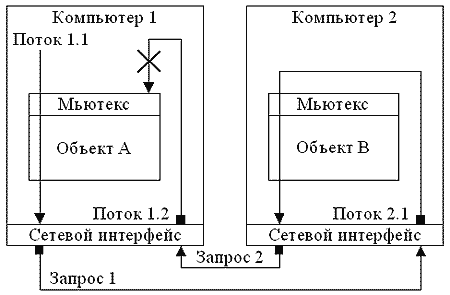
Рисунок 2. Дидлок при удаленной
рекурсии
Здесь и далее, удаленный вызов не обязательно
означает вызов объекта на другом компьютере. То же самое происходит, если объект
находится в другом процессе на том же самом компьютере. В обоих случаях,
логически последовательная операция выполняется в различных потоках. Под
локальным вызовом будем подразумевать вызов, не выходящий за границы одного
процесса.
Возможность возникновения тупиковой ситуации
требует от программиста, при написании кода объекта, отслеживать его связи с
другими объектами системы, чтобы избежать рекурсии и согласовать с кодами других
объектов порядок вызова методов. Это опять нарушает основополагающий для ООП
принцип инкапсуляции, который, в данном случае, можно сформулировать так:
программист должен иметь возможность создавать и модифицировать код объекта,
руководствуясь только описанием его интерфейса, не имея представления о
внутреннем устройстве других объектов и структуре системы в целом. И
это - не пустая догма. Для систем, в которых этот принцип не соблюдается, после
достижения определенного уровня сложности, стоимость поддержки и развития
возрастает экспоненциально, а надежность - так же экспоненциально падает.
Декларируя, на словах, принцип инкапсуляции, многие (если не все) современные
объектные системы, на деле, не соответствуют ему, поскольку в них не решена
описанная выше проблема.
Посмотрим, что здесь можно сделать. Когда мы
выполняем исходящий вызов, мы не можем запретить 'своему' потоку рекурсивно
вызывать методы нашего объекта. Почему бы тогда не разрешить 'чужим' потокам
делать это? В самом деле, раз уж мы все равно вынуждены соблюдать правила 2 и 3,
нет никакого смысла блокировать объект во время исходящего вызова. Таким
образом, непосредственно перед выполнением исходящего вызова, мы можем
освободить мьютекс, а сразу после возврата из него - вновь захватить. Это
позволит объектам выполнять вызовы от других потоков во время ожидания ответа от
других объектов. Возникновение дидлока будет исключено, а производительность и
время отклика при этом могут улучшиться очень существенно, за счет более
эффективного использования многозадачности.
Таким образом, соблюдение правил 2 и 3, при
использовании соответствующих методов блокировки позволяет:
- Обеспечить консистентность данных независимо от наличия рекурсии
- Гарантировать отсутствие тупиковых ситуаций независимо от структуры системы
- Существенно повысить производительность за счет более эффективного
использования многозадачности
Надеюсь, мне удалось вас убедить.
Как всегда бывает, полному счастью мешает одна
проблема. Она связана с передачей и возвратом параметров по ссылке. Если мы
передаем вызываемому объекту B указатель на локальные данные вызывающего объекта
A, объект B получает к ним прямой доступ. Если при этом объект A будет выполнять
другой вызов, консистентность его данных может быть нарушена. Прямая передача
параметра по ссылке должна быть исключена. Необходимо промежуточное копирование.
Собственно, при удаленном вызове, оно и так выполняется, когда передаваемые
данные пакуются в сетевые пакеты (так называемый маршалинг). Однако, при этом,
освобождать блокировку объекта следует после маршалинга передаваемых данных, а
захватывать - перед демаршалингом принимаемых. Это требует переноса логики
блокировки внутрь кода, выполняющего маршалинг. Без модификации самой объектной
среды, с помощью только прикладных библиотек, этого добиться нельзя.
При выполнении локальных вызовов, промежуточное
копирование может снизить производительность, особенно при передаче больших
массивов данных. Чтобы этого избежать, можно воспользоваться логическим
копированием с разделением страниц виртуальной памяти по принципу copy-on-write.
При этом физического копирования данных не происходит, а операция копирования
сводится к модификации таблиц управления виртуальной памятью и выполняется очень
быстро. Причем, такое копирование можно использовать и для передачи данных между
разными процессами на одном компьютере. К сожалению, использование разделяемой
виртуальной памяти в большинстве современных ОС ограничено специальным образом
создаваемыми областями. Нужно либо обеспечить, чтобы вся память, используемая
объектной системой, включая кучу и стек, принадлежала разделяемой области, либо
использовать принципиально иной подход к управлению виртуальной памятью на
уровне ядра, чтобы любую страницу можно было разделить в любой момент. Windows
CE, например, позволяет это сделать с помощью вызова VirtualCopy. Базовые версии
Windows почему-то не имеют этой функции. В принципе, функции управления
разделяемой памятью, имеющиеся в Windows и POSIX API, позволяют создать
соответствующую среду, где вся память будет разделяемой. Но это довольно
непросто, так как эти функции ориентированы на другие задачи.
На первый взгляд, может показаться, что данные,
расположенные в стеке, не нуждаются в копировании, так как они видны только
одному потоку. Определив, по значению адреса, что передаваемые данные находятся
в области стека, можно было бы исключить их промежуточное копирование. На самом
деле, определить область видимости данных намного сложнее. Программист может,
например, временно присвоить локальной переменной объекта указатель на строку,
находящуюся в стеке. Подобные ситуации можно считать достаточно редкими но, в
принципе, их никто не запрещал. Поэтому, в полностью корректной системе, к стеку
нужно относиться так же, как и к другим областям памяти. В простой системе,
можно исключить копирование данных стека, оговорив в руководстве для
программиста запрет на их связывание с данными объекта.
Необходимое замечание относительно статических
данных, доступных одновременно всем экземплярам объекта: использования
статических данных следует всячески избегать. Если несколько объектов имеют
доступ к общей области данных, они должны рассматриваться как единый объект и
блокироваться одновременно. Это может снизить производительность системы. Если
требуется обеспечить доступ к данным из нескольких объектов, такие данные лучше
выделить в отдельный объект.
Таким образом, обеспечение корректного
непротиворечивого взаимодействия объектов требует некоторой модификации
существующих сегодня объектных сред. Но игра стоит свеч. Программисту не надо
будет ломать голову над тем, как распределить работу по потокам, чтобы
обеспечить высокую производительность, сохранив консистентность данных и избежав
взаимных блокировок. Система сможет сама использовать потоки максимально
эффективным образом, прозрачным для программиста, а дидлоки будут исключены.
Это - так называемый естественный или неявный параллелизм.
Известный специалист по COM Дон Бокс (Don Box),
в одной из своих статей, сравнил потоки с бензопилами, которые могут быть очень
полезны, но, при неосторожном использовании, могут нанести большой вред как
самому пользователю, так и окружающим. Развивая эту мысль, можно сказать, что
разработчики современных операционных систем предлагают программистам все более
мощные инструменты, нисколько не заботясь о том, будет ли их использование
безопасным и удобным. Результаты этого ощущает пользователь, когда у него вдруг,
по непонятным причинам, зависает или падает программа. Проще всего объяснить все
недостаточной квалификацией программиста. Однако, во-первых, человеческий мозг
плохо приспособлен для решения некоторых типов задач, в частности, анализа
взаимодействия параллельных процессов, а во-вторых, ситуация с кадрами в отрасли
такова, что 'других писателей у нас нет'.
Идеальная система должна обеспечивать
максимальную эффективность всего цикла жизни программного обеспечения: от
разработки до поддержки. Такая система должна брать на себя рутинные функции,
вроде оптимального распараллеливания вычислений и блокировки, освобождая
программиста для более творческой работы. Пользуясь той же аналогией, на смену
бензопиле должен прийти интеллектуальный робот, способный проложить просеку в
заданном направлении, затратив минимум топлива и не подвергая никого
опасности.
Языки программирования: разное
|
