|
Сьюзен Фицжеральд, Лео Бикнелл
Если вы устали выполнять роль регулировщика трафика в сети, то нижеследующие
дорожные указатели должны помочь проложить путь через глобальную сеть.
С объединением приложений для голоса, видео и данных в одной общей
высокоскоростной магистрали, администраторы сетей оказались в незавидном
положении главных распределителей одного из наиболее ценных активов компании -
высокоскоростной глобальной сети. Однако новизна этой задачи давно утратила свой
первоначальный блеск, и администраторы превратились в заурядных регулировщиков
трафика между пользователями.
Когда все работает как часы, позиция надсмотрщика необременительна. Но с
появлением новых проблем администратор оказывается сидящим на горячих углях. По
мере проявления всяких глюков наиболее насущным вопросом становится возможность
диагностирования современных сетей с помощью существующих методов.
Несмотря на то что традиционные методы и способы применимы для
диагностирования сетевых проблем вообще, высокоскоростные глобальные сети
привносят свои трудности. Иначе говоря, чем гибче и масштабируемее сеть, тем
ощутимее потребность в эффективном тестировании и управлении. В этой статье мы
рассмотрим наиболее часто встречающиеся проблемы в широкополосных сетях. Наша
дискуссия коснется главным образом нижележащих сетевых соединений на базе
широкополосных транспортных протоколов второго уровня.
Два широкополосных транспортных протокола, изучением которых мы займемся, -
это frame relay и его наследник ATM. Хотя протоколы сетевого уровня и выходят за
рамки нашей статьи, необходимо помнить, что они ответственны не только за
проблемы маршрутизации.
ОБНАРУЖЕНИЕ СБОЯ
Несмотря на все многообразие сетевых проблем, они могут быть отнесены, как
правило, либо к проблемам связи, либо к проблемам производительности.
Проблемы связи включают разрыв надежного пути от отправителя к получателю.
При всей трудности диагностирования их воздействие на сеть очевидно.
Проблемы производительности (такие как потеря данных) не столь заметны, но
более распространены в глобальных сетях. Тремя основными переменными в общем
уравнении производительности сети являются доступность, задержка и
загруженность. Если вы хотите получить аккуратную оценку производительности, то
эти факторы необходимо рассматривать в совокупности.
Какой подход к диагностированию сети будет наиболее эффективен, зависит от
того, с каким уровнем модели OSI вы имеете дело. В глобальной сети вопросы
физического уровня не столь сложны: сетевой уровень, ответственный за вычисление
наиболее эффективного маршрута к месту назначения пакета, а также изменений в
сетевой топологии, диагностировать гораздо труднее. Вне зависимости от того,
какой уровень вы диагностируете, здравый смысл и надежная технология способны
принести огромную отдачу.
Первый шаг в диагностировании любых сетевых проблем состоит в определении
места, где произошел сбой. Точная диаграмма топологии сети во время этой фазы
просто бесценна.
Существует несколько методов и инструментов определения места сбоя.
Простейший подход предполагает применение такого недорогого и распространенного
инструмента, как ping. Поскольку ping базируется на IP, вам необходимы как
минимум два устройства TCP/IP, по обеим концам сети. Ping может использоваться
для проверки любого сетевого компонента с IP-адресом. Такой тест дает информацию
не только о наличии связи, но и об общей задержке, как показателе
производительности сети.
Ping настолько полезный инструмент, что несколько основных производителей
маршрутизаторов расширили его возможности и предложили распределенный процесс
ping. Этот малоизвестный (и потому нечасто используемый) инструмент позволяет
распространять информацию о связи и производительности по сети. При обычном
процессе ping изоляция вышедших из строя компонентов или сетевых сегментов
начинается с посылки запроса c ближайшего устройства (см. Рисунок 1).
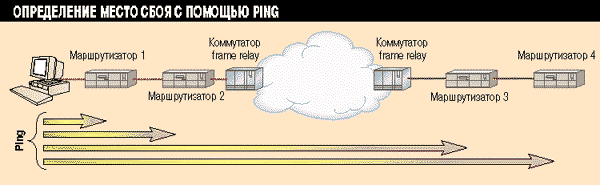
Рисунок 1.
Определить место сбоя можно посредством
посылки запроса ping с ближайшего доступного устройства, пока вы не достигнете
неотвечающего или неисправного устройства.
Безуспешные тесты ping или те из них, что приносят неожиданные результаты,
следует дополнить тестами traceroute для соответствующих хостов. Как следует из
названия, traceroute позволяет отследить путь или маршрут пакета через сеть.
Тесты ping и traceroute, используемые независимо или вместе, определяют путь,
которым пакет следует по сети к адресату, а также время, за которое он его
достигает.
Основываясь на результатах тестов ping и traceroute, администратор может
изолировать ту часть сети, где произошел сбой. После этого можно начинать
настоящую диагностику.
РАЗРЫВЫ ЦЕПИ
Подавляющая часть проблем в глобальной сети связана с разрывами цепи. К
сожалению, источник таких осложнений не всегда очевиден. Иногда для
диагностирования этого достаточно простого компонента сети приходится проводить
несчетные часы.
В высокоскоростных глобальных сетях проблемы с каналами связи те же самые,
что и в обычных низкоскоростных сетях. Основное различие между высокоскоростными
и низкоскоростными каналами состоит в методах обрамления и кодирования.
Обнаружить ошибки в обрамлении и кодировании можно только с помощью
специализированных инструментов для тестирования. Наиболее широко используемыми
инструментами являются анализаторы связи для высокоскоростных каналов; эти
инструменты отличаются от тех, что предназначены для диагностики каналов уровня
T-1 и ниже.
Более традиционные анализаторы зачастую не в состоянии справиться с объе-мом
данных, характерным для скоростей DS-3 и выше. Кроме того, использование средств
отладки большинства маршрутизаторов в сети может застопорить работу этих систем
при больших и даже умеренных нагрузках. Например, канал OC-3 способен заполнить
диск на 10 Гбайт менее чем за 10 минут, и, очевидно, он не по зубам многим
традиционным анализаторам данных.
Так каким же образом можно диагностировать каналы OC-3 и OC-12 без
анализатора? В большинстве ситуаций процедура диагностирования предполагает
обращение к провайдеру услуг связи. Если такой путь неприемлем, то вы должны
будете сами заняться типичными проблемами и решениями.
Прежде всего проблема может просочиться в вашу сеть на этапе приобретения
канала. Это весьма ответственная процедура даже для опытных администраторов
сетей. Заказ канала - половина дела, так как от него зависит правильное
обрамление, кодирование и физический интерфейс.
Обеспечение надлежащей синхронизации также имеет важное значение. В качестве
общего правила синхронизация всех каналов быстрее 56 Кбит/с должна
осуществляться в соответствии с принятой оператором связи. Маршрутизаторы и
другое оборудование в помещении заказчика необходимо настроить на внешний
тактовый генератор.
В Соединенных Штатах варианты обрамления (framing) для каналов весьма
немногочисленны. Девяносто процентов всех каналов заказываются с обрамлением ESF
и кодированием B8ZS. ESF применяется в каналах T-1 и содержит бит для
синхронизации и других целей. B8ZS помогает CSU/DSU надежным образом
восстановить синхронизацию данных.
Международные стандарты определяют два типа обрамления и кодирования. Четыре
возможные перестановки меняются от страны к стране. При развертывании каналов,
охватывающих более чем одну страну, вы должны использовать одинаковое
кодирование и обрамление по обоим концам канала.
Однако каналы DS-3 предусматривают иные варианты обрамления: Header Error
Check (HEC) и C-Bit Physical Layer Conversion Protocol (PLCP), причем C-Bit PLCP
- наиболее распространенный вариант. (C-Bit PLCP - это спецификация,
отображающая ячейки ATM на физическую среду и определяющая некоторую управляющую
информацию.)
Во время инсталляции местный оператор связи должен протестировать каналы.
Этот этап часто игнорируется, в результате администраторы сетей и ИС вынуждены
диагностировать не только канал, но и нейтральную территорию между окончанием
канала и оборудованием. Сегодня интеллектуальные гнезда позволяют проводить
петлевой тест для каналов на 56 Кбит/с и выше со станции оператора связи. Часто
используемые для тестирования пригодности сетевого интерфейса, петлевые тесты
предусматривают посылку сигнала, который затем посылается назад отправителю из
определенной точки на маршруте.
После выполнения своего петлевого теста оператор связи может провести
отдельный петлевой тест из конца в конец на оборудовании в вашем помещении
(Customer Premises Equipment, CPE). Это позволяет не только протестировать
канал, но и проверить проводку на демаркационном участке между оператором связи
и оборудованием абонента. За небольшую дополнительную плату оператор связи может
проложить кабель от отсека связи до вашего оборудования. Такие затраты себя
окупают, так как проблемы чаще всего возникают на последнем отрезке
протяженностью 30-50 м.
При развертывании новой технологии несоответствие уровня сервиса ожидаемому
имеет место довольно часто, особенно это касается сервисов ATM. В частности,
время от времени они оказываются недоступны, так как многие проблемы еще в
новинку даже операторам связи. Прежде чем браться за обширное диагностирование
сети, следует изучить статистику маршрутизатора или анализатора об изменении
состояний несущей; в результате вы получите информацию, сколько раз
задействовался канал и какие соединения были потеряны. Чтобы эти данные имели
смысл, они должны иметь отметку о времени в целях ведения записей о
предыстории.
FRAME RELAY И PVC
Frame relay, наиболее распространенная сегодня в США широкополосная
технология, доступна для коммерческого использования вот уже семь лет. За эти
годы была собрана масса сведений о поведении протокола; одна часть имеющихся
данных представляет собой хорошо документированную информацию, собранную
различными производителями, поддерживающими frame relay, другая же часть исходит
от Frame Relay Forum.
Не менее полезны встроенные средства управления рабочими характеристиками
сети frame relay. Наряду с огромным массивом данных по технологии, они заметно
упрощают диагностирование сети frame relay.
Как и в случае любых других каналов, процесс предоставления услуг frame relay
таит потенциальные проблемы. При первоначальной инсталляции frame relay задается
относительно небольшое число обязательных параметров. Некоторые из них имеют
отношение к управляющей информации, поэтому вы должны убедиться, что схема
управления маршрутизатора соответствует используемой сервис-провайдером. Если
сервис не доступен после задания начальной конфигурации, то в первую очередь
необходимо проверить следующие настройки: параметры управляющей информации,
синхронизацию и обрамление/кодирование.
Frame relay поддерживает три разных стандарта управляющей информации: Local
Management Interface (LMI), Annex D и Annex A. LMI, усовершенствованная версия
базовой спецификации frame relay, поддерживает глобальную адресацию,
многоадресную рассылку, информацию о статусе и т. п. Annex D, интерфейс
управления каналом frame relay, является стандартом ANSI. Annex D принят по
умолчанию большинством операторов связи в США. При правильной конфигурации
системы вы можете увидеть, как управляющая информация передается с
маршрутизатора на коммутатор сервис-провайдера и обратно. По умолчанию они
обмениваются данными каждые 10 секунд. Annex A используется, главным образом,
при международной связи.
После проверки параметров управляющей информации, синхронизации и
обрамления/кодирования наступает очередь проверки параметров DSU/CSU. Успех
обмена управляющими пакетами между коммутатором frame relay и маршрутизатором
зависит от успешной доставки кадров комбинированным устройством DSU/CSU.
В DSU/CSU должны быть правильно настроены три основных параметра:
синхронизация, обрамление и кодирование линии. Как упоминалось в разделе о
диагностировании канала, сеть обычно обеспечивает синхронизацию с внешним
тактовым генератором. Кроме того, DSU/CSU следует конфигурировать таким образом,
чтобы обрамление данных было правильным (обычно это формат ESF с кодированием
B8ZS).
Иногда сетевой адрес получателя становится недостижим по прошествии
некоторого периода времени. Наиболее вероятная причина такого рода потери
сервиса в отказе постоянного виртуального канала (Permanent Virtual Circuit,
PVC). На основании управляющей информации, которой маршрутизатор и коммутатор
обмениваются между собой, вы можете определить, что PVC был удален или добавлен
или что он доступен или недоступен. Эти данные собираются и просматриваются с
консоли маршрутизатора либо с помощью сетевого анализатора.
Если интерфейс обслуживает несколько PVC и только один из них отказал, то
отказавший PVC придется диагностировать дальше. Это можно сделать с помощью
обходного (backdoor) IP-адреса (см. Рисунок 2); если все PVC через данный
интерфейс недоступны, то причина скорее всего в физическом интерфейсе или
канале.
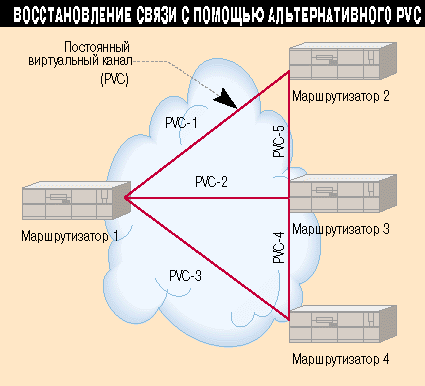
Рисунок 2.
Проверить наличие соединения можно,
попытавшись связаться с подозрительным устройством напрямую. Если сделать это не
удается, то попробуйте использовать обходной IP-адрес. В данном примере трафик
не проходит от маршрутизатора 1 к маршрутизатору 2 через PVC-1, но взамен, чтобы
связаться с маршрутизатором 2, вы можете попробовать альтернативный путь через
PVC-2 и PVC-5.
Установив, что проблема в PVC, проверьте номера DLCI (DLCI идентифицирует
виртуальный канал между маршрутизатором и коммутатором, по которому между ними
передаются данные и управляющая информация). Проверив номера DLCI, вы можете
быть уверены, что маршрутизатор конфигурирован в соответствии со схемой
нумерации, используемой сервис-провайдером frame relay.
Наконец, убедитесь, что сервис-провайдер активизировал данный PVC и что он
функционален. PVC конфигурируются на коммутаторах сервис-провайдера, поэтому на
данном этапе вы должны будете обратиться к оператору связи, так как это его
проблема.
Длительное время сервисы frame relay покупали из-за того, что данная
технология обеспечивает пропускную способность по требованию. В прошлом два
крупнейших оператора связи предлагали сервисы с нулевым значением
гарантированной скорости передачи (Committed Information Rate, CIR). Равенство
CIR нулю означает, что если есть свободная пропускная способность, то данные
будут передаваться по сети, но сервис-провайдер ее не гарантирует. Однако, как
только загруженность сети провайдера возрастает, общая производительность
заметно снижается.
Сегодня сервис-провайдеры предлагают различные скорости CIR, причем при
наличии пропускной способности абоненты могут передавать данные и с превышением
CIR. Если ваша сеть постоянно сталкивается с перегрузками, то, скорее всего,
заложенная схема чересчур зависима от режима пакетной передачи или
предоставляемая сервис-провайдерам пропускная способность слишком мала.
Чтобы определить, что снижение производительности является результатом
перегрузки в сети сервис-провайдера, время отклика необходимо финансировать в
течение всей недели, - так вы сможете установить, что снижение имеет место
приблизительно в одно и то же время каждый день. Часы пик, когда корпоративные
сети (и, следовательно, сети провайдеров) наиболее загружены, приходятся на
период с десяти утра до двух дня. Если такая зависимость характерна и для вашей
сети, а отбрасываемые данные чувствительны ко времени, то надо провести
тщательный мониторинг сервиса frame relay с целью установления необходимости
заключения контракта на более высокую CIR. Если CIR значительно превосходит
уровень трафика, то сервис-провайдер не обеспечивает максимальную
гарантированную пропускную способность.
ATM: СКОРЕЕ ИСКУССТВО
По самой своей природе ATM представляет целый ряд задач в области
диагностирования. Высокоскоростные сети ведут к таким проблемам, как задержка и
потеря данных или, в случае ATM, ячеек.
В зависимости от типа сервиса начальная конфигурация сервиса ATM может
варьироваться от несложной до умопомрачительной. При этом обычно
подразумевается, что такие элементы, как уровень адаптации ATM (он определяет
процесс преобразования информации с верхних уровней в ячейки ATM), PVC и
параметры многоадресной передачи, заданы правильно. Если это так, а канал все же
не функционирует, то проверьте конфигурационные параметры кодирования ATM. По
умолчанию данный параметр активизируется на коммутаторе и блокируется на
маршрутизаторе.
Одним из основных средств тестирования соединения ATM служат ячейки
Operation, Administration, Maintenance (OAM). Эти ячейки обеспечивают средства
обратной связи на уровне виртуальных каналов, и таким образом они помогают
проверить функционирование канала и маршрутизатора. С упрощенной точки зрения
эти ячейки можно рассматривать как сообщения о том, что устройство продолжает
работать.
Тестирование с помощью ячеек OAM используется в других протоколах глобальных
сетей вот уже несколько лет, а его результаты служат для измерения характеристик
конкретного соединения. Этот метод поддерживается большинством коммутаторов ATM
для глобальных сетей.
На сегодняшний день потеря ячеек является наиболее серьезным вопросом
управления и диагностирования. Одна из причин заключается в том, что небольшие
53-байтные ячейки ATM отправляются в довольно крупных пакетах. Следовательно, в
случае необходимости повторной передачи пересылать придется крупные массивы
данных.
К сожалению, эту проблему нельзя решить включением или отключением
какого-либо управляющего бита. Правила формирования трафика позволяют
устройствам "договориться" об уровне трафика. Однако не все
коммутаторы ATM и конечные устройства формируют трафик одинаково, а это ведет к
тому, что трафик, будучи успешно передан одним устройством, игнорируется другим,
хотя на первый взгляд они функционируют в соответствии с одними и теми же
критериями. Данная проблема наиболее типична для конечных устройств, когда они
пытаются отправить данных больше, чем разрешено входным коммутатором, - такая
ситуация ведет к значительным потерям ячеек.
Ячейки могут быть потеряны и в случае, когда транзитный коммутатор на пути
следования данных начинает отбрасывать ячейки в целях рассасывания затора. Это
может вызвать серьезные проблемы для таких пакетных протоколов, как IP. При
потере ячейки весь пакет оказывается испорчен, что, в свою очередь, увеличивает
процент потерь для высокоуровневых протоколов, поскольку передавать приходится
весь пакет целиком. В результате потеря 2% ячеек ATM может привести к порче 15%
пакетов.
Как и в случае frame relay, способ управления пакетной передачей состоит в
тщательном мониторинге в целях определения наличия адекватной емкости сети. В
качестве общего правила, доступная пропускная способность высокоскоростной сети
должна превышать ваши текущие требования в два раза, если, конечно, вы хотите,
чтобы потери ячеек были минимальны. Такое решение недешево, но оно может
оказаться единственным способом обеспечения достаточной емкости.
Свою роль в определении необходимой емкости играет и исходная архитектура
сети. Хорошая документация позволит оптимизировать емкость и избежать потери
ячеек.
Наибольший эффект потеря ячеек имеет при больших нагрузках - т. е. именно
тогда, когда необходимо, чтобы сеть работала надежно. Производители коммутаторов
решают эту проблему посредством предоставления новых функций типа ранней
отбраковки ячеек, при которой коммутатор старается отбросить ячейки из одного
пакета, а также интеллектуальной отбраковки ячеек, при которой коммутатор
отбрасывает только целые пакеты. Эти функции носят пока экспериментальный
характер и возлагают на коммутаторы ATM дополнительную нагрузку по обработке
трафика.
Другим важным вопросом в случае сетей ATM является управление задержкой.
Многие сетевые протоколы, в том числе TCP/IP, весьма чувствительны к задержкам в
сети. Администраторы сетей с длительной задержкой сталкиваются с этой проблемой
довольно часто; наиболее показательный пример - спутниковые каналы.
Подобные ограничения могут приводить к тому, что приложения или пользователи
окажутся не в состоянии добиться скоростей, которых в принципе сеть позволяет
достичь. По существу сеть оказывается чересчур быстрой для приложения. Особенно
часто это случается в локальных сетях, где пользователи могут иметь канал к
своим настольным системам, эквивалентный OC-3, но отправлять и принимать данные
с намного меньшей скоростью.
При счастливом стечении обстоятельств эту проблему можно решить посредством
настройки параметров протокола на пользовательском компьютере. Менее удачливым
придется обновлять сетевые стеки.
ОБУЧЕНИЕ ДИАГНОСТИРОВАНИЮ
Беспроблемных сетей нет, поэтому навыки диагностирования необходимо
совершенствовать. Если вы делаете только первые шаги в мире сетей, то наилучший
путь - набираться опыта при решении конкретных проблем. Несмотря на всю важность
специального технического образования, хороший сетевой инженер отличается от
обычного прежде всего здравым смыслом.
Собственный опыт незаменим. Практические знания о динамике крупной
магистральной сети можно получить в центре управления такой сети. Многие сетевые
инженерные организации и университетские вычислительные лаборатории имеют
необходимое оборудование, а это реальная возможность попрактиковаться в
управлении сетью, так как вам волей-неволей придется сталкиваться с самыми
разнообразными проблемами сети.
Сетевым протоколам и архитектурам посвящено немало книг, но, к сожалению, по
большей части они игнорируют такую задачу, как диагностирование. Восполнить этот
пробел помогают производители аппаратного и программного обеспечения,
предлагающие очень хорошие руководства по диагностированию. Однако определенная
осторожность в данном вопросе не помешает, поскольку некоторые из этих компаний
придерживаются своего, иногда весьма тенденциозного взгляда на вещи.
Обучение диагностированию на курсах позволяет пополнить багаж знаний,
конечно, при правильном выборе таких курсов: качество совершенно непредсказуемо,
так как многое зависит от опыта инструктора. Практические лабораторные работы
при подобном обучении абсолютно необходимы. Прежде чем пойти на курсы,
поинтересуйтесь, что за человек будет инструктором и как оборудованы классы.
Постепенно начинают появляться и посвященные исключительно проблемам
диагностирования выставки. Они предоставляют отличные возможности посетить
обучающие семинары и, что более важно, пообщаться с коллегами. Одной из таких
выставок является Network Analyst Forum, финансируемая Pine Mountain Group
(www.pmg.com/nafhome.htm).
При поиске наилучших средств обучения помните, что сети - как отпечатки
пальцев: ни одна из них не походит на другую. Чтобы рекомендации и принципы
диагностирования оказались полезны для вас, они должны рассматриваться в
контексте вашей конкретной сети.
В конечном итоге возможность поддержания сети в работоспособном состоянии во
многом определяется ее базовой архитектурой. Если пользователи сталкиваются с
перебоями в работе сети, то настало время достать документацию с описанием
топологии сети и проанализировать, какие протоколы и приложения используются в
ней. Возможность полностью переделать сеть предоставляется редко, но поэтапные
изменения способны привести к значительному улучшению работы сети без риска
нанести ущерб сетевой инфраструктуре.
Прежде чем браться за реализацию каких-либо значительных изменений в сети,
определите ее эффективность. Для получения объективных оценок многие компании
обращаются к сторонним организациям. Должным образом выполненное определение
характеристик сети дает поддающиеся количественной оценке данные, в том числе
того, насколько эффективны произведенные улучшения.
Значительный прогресс достигнут также в увеличении надежности и стабильности
сети. Появление таких технологий, как RSVP, и таких функций, как качество услуг
и маршрутизация в соответствии с заданными правилами, снижает нагрузку по
администрированию, упрощает прогнозирование производительности сети и, как
следствие, управление сетью. Хотя эти средства и облегчают жизнь сетевого
инженера, возможность быстро и точно диагностировать сетевую проблему
по-прежнему остается бесценной.
ПРОВЕРКА НА ДОРОГЕ
СОС: семь опасных симптомов
В природе бедствию обычно предшествуют предзнаменования; покой перед штормом
- классический тому пример. Конечно, человек мало что может сделать, чтобы
предотвратить шторм или наводнение, однако постоянный контроль за
функционированием сети поможет избежать многих неприятностей. Ниже мы приводим
наиболее характерные признаки того, что вашей сети грозит опасность.
1. Максимальная загруженность магистральных каналов превосходит
70%.
2. Потеря кадров/ячеек превышает 2-3%.
3. Задержка в сети возрастает более чем на 10%.
4. Биения постоянных виртуальных соединений. Это происходит, когда
заявленный маршрут между двумя узлами проходит то по одному, то по другому пути,
потому что отказ транзитного интерфейса привел к проблемам в сети.
5. Увеличение числа несовпадений контрольных сумм.
6. Значительное превышение гарантированной скорости обмена, в
результате чего в периоды пиковой нагрузки многие данные теряются.
7. Приложения сталкиваются постоянно с тайм-аутами.
Литература по Internet
| 