|
Компилятор: Visual C++
Сразу оговорюсь, программа читает графические файлы как бинарные данные,
раскодирует их и выводит изображение. При этом не используются никакие
библиотеки или специальные классы. Так что не ищите тут примеров использования
библиотек/классов для вывода изображений. Программа предназначена как пример дял
тех, кто возможно захочет написать свою смотрелку изображений, независимую от
ОС, платформы или чего еще. Итак программа умеет просмотривать 5 типов файлов
*.pcx , *.bmp, *.tiff", "*.gif", "*.jpg". Несколько
слов об особенностях просмотра:
PCX
Реализована возможность просмотра 256 цветных изображений и
изображений с глубиной цвета 24 бит. (Просмотр изображений с глубиной цвета
1,2,4 бит уже реализован другими авторами,и даже выложен на этом же сайте:) ).
принцип, как оно храниться в файле(структура файла):
1 сначала идет заголовок.
2 потом последовательность байт, описывающих
изображение
3а если 256 цветное изображение, то в конце файла *.pcx храниться
палитра цветов, то есть 256 троек по три байта - красаня компонента, зеленая и
синяя. Последовательность байт в самом изображении определяет номера цветов в
палитре. таким образом каждому пикселу отвечает один байт, и этот байт - номер
цвета пиксела в палитре.
3б если изображение с глубиной цвета 24 бит (16 млн
цветов) то палитра не зраниться, и цвет каждого пиксеал закодирован в
последовательности байт, описывающих изображение. На каждый пиксел приходиться
по три байта - по одному для красной компоненты цвета, зеленой и синей.
Считаеться, что изображение храниться построчно. То есть сначала описывается
1 строка изображение, потом вторая.... При этом каждая строка может сжиматься,
чтобы занимать меньше места. принцип сжатия довольно простой, если в строке есть
несколько подряд идущих одинаковыых байт,то они заменяються на два байта: первый
содержит укащание, что это сжатая группа байтов и их количество (первые два бита
1 признак сжаточ группы, послдение 6 бит - количество байт в группе), второй
байт = одному из байтов сжимаемой группы. размер и количество строк описываються
в заголовке.
24битное изображение:
палитры нет, каждая строка изображение
описываеться тремя строками в файле. RRRRRR... строка компонент красного цвета
всех пикселов строки GGGGGG... --||-- зеленого цвета BBBBBB... синего выделив
первый байт из каждой строки мы получим соответственно красную, зеленую и синюю
компоненты цвета первого пиксела в этой строке изображения. выделив второй байт
- компоненты цвета второго пиксела и т.д. При этом в каждой строке данные могут
быть сжаты указанным выше алгоритмом. Для более подробного описания формата pcx
см файл с описаниями форматов.
BMP
реализован просмотр 256 цветных палитровых изображений и 24
битных. опять же после заголовка (в котором содержиться палитра, если на есть)
следует последовательность байт, описывающих изображение. Для палитровых
изображний каждый байт - номер пиксела в палитре, для 24 битных - каждые три
подрядидущих байта описывают компоненты цвета соовтетствующего пиксела.
Особенность такого изображения - избражнеие тоже храниться по строкам,
количество байт в каждой строке должно быть кратным 4(насколько я помню)
Этот формат довольно хорошо освещен и в MSDN и в прилагаемом файле, и вообще
проще использщовать функцию LoadImage HBITMAP
sqrt_x=(HBITMAP)LoadImage(0,"res/sqrt_x.bmp",IMAGE_BITMAP,0,0,LR_LOADFROMFILE);
Существуют два вида bmp - для виндов и для MAC'ов (насколько я понял) они
различаються заголовками. Реализован просмотр bmp только для виндов.
TIFF
самый "толстый" формат. он задумывался наверное
чтобы быть универсальным. Описания довольно грмоздкое, так что тут опишу только
некоторые моменты. в файле может быть несколько картинок. В начале файла идет
небольшой заголовок. в нем есть поле указывающее на заголовок первой. заголовок
первой - не имеет фиксированного размера и фиксированных полей. Он состоит из
некоторого набора тегов, каждый из которых определяет некое свойство
изображения. вообще этих тегов очень много, в проге использованы далеко не все.
изображение может описываться в файле одной последовательностью байт, или
несколькими (как написано в описании - для более быстрого вывода на экран и
экономии памяти.. гм, а приходиться усложнять код для возможности просмотра и
таких изображний:):) ) есть тег, описывающий массив смещений в файле на каждую
такую подпоследовательность, и другой тег, описывающий массив длин таких
подпоследовательностей.
В проге реализован просмотр несжатых палитровых изображений и несжатых RGB -
изображений. Причем при глубине цвета 36 бит наблюдаеться некий глюк - несовсем
точная цветопередача, очевидно это из-за того, что эти 36 бит зарзаботчики tiff
и зазработчики HBITMAP рассматривли по разному: у одних это 3 компоненты цвета и
альфа канал, у других - просто три компоненты цвета, но каждая больше чем по 8
бит.
GIF Реализован просмотр всех типов GIF файлов кроме анимированных. На
некоторых файлах проявляется глюк: изображение оказывается
"перетянутым". В чем там дело я так и не догадался.
Описывать сам формат
GIF довольно долгое занятие, тем более, что это уже сделали, причем лучше, чем
бы мог я. Скажу только, что данные внутри файла сжаты методом
LZW.
JPEG
Теперь несколько слов о формате JPEG. Он, пожалуй, самый трудный для
реализации, но и сжимает лучше всего. Для этого формата существует множество
"подформатов", которые различаются порядком записи элементов заголовка
и частей изображения. В проге реализован наиболее распространенный
"подформат" JFIF (Причем не полностью, но об этом ниже).Итак, дока по
JPEG'у Самое
интерестное в том, что в инете есть множество описаний этого формата, правда они
не всегда совпадают, а то и явно противоречат друг другу. Также нашлась прога на
паскале, которая должна выводить на экран файлы в формате jpeg (только она не
захотела работать..). Посему я решил выложить своию прогу и некоторые
соображения касательно формата жпег, полученые опытным путем. Итак. Формат жпег
применим только для картинок с глубиной цвета 24 бита (16 млн цветов). Сначала
изображение переводится из RGB в YCbCr, где для каждого пикселя сохранются
- Y - яркость,
- Cb - компонента голубого цвета.
- Cr - компонента красного цвета.
Более подробно об этом, включая формулы перевода читайте в доке. Кстати, если
взять цветное изображение, перевести его в yCbCr, а потом оставить только
компонент Y, то изображение в оттенках серого. Все изображение переводится
разбивается на блоки 8х8 пикселей.
Затем начинаются шифры. Для каждого
пиксела сохраняется компонента Y, тк она несет наибольшее количество информации.
Для каждых четырех пикселов
12
34
сохраняется одно значение компоненты
Cb, и одно значение компоненты Cr. То есть, компоненты Cb получается одна на 4
пиксела. Потом выбирается из блоков 8х8 блок 16х16, состоящий из четырех блоков
8х8. Этот блок называется минимальной единицей кодирования (MCU). На этот блок
16х16 сохраняется 4х8х8 значений компонента Y,8х8 значений компонента Cb, и 8x8
значений компонента Cr. То есть 4 блока 8х8 компонента Y, и по одному блоку 8х8
компонент Cb и Cr. Эти блоки идут в жпег-файле последовательно, сначала 4 блока
компонент Y, потом по одному блоку компонент Cb и
Cr.
(Y1)(Y2)(Y3)(Y4)(Cb)(Cr) (Y1)(Y2)(Y3)(Y4)(Cb)(Cr)
(Y1)(Y2)(Y3)(Y4)(Cb)(Cr)
в изображении :
Y1 Y3
Y2 Y4
На самом деле, может быть так, что одна компонента Cb отвечает не 4 пикселям,
а двум (2х1 или 1х2) или 6 пикселам (2х3). А одна компонента Cr отвечает другому
количеству пикселей, например 3 (3х1). Все это определяется в заголовке и
называется дискретизацией по вертикали и горизонтали. Так например, если
дискретизация по вертикали 1, а по горизонтали 2, то эта компонента
соответствует блоку пикселей 2х1 (2 по горизонтли и 1 по вертикали). Как правило
, в большинстве рисунков, для Y дискретизация по горизонтали и вертикали равна
1, то есть одна компонента Y отвечает 1 пикселу; а у компонент Cb и Cr
дискретизация по горизонтали и вертикали равна 2. В программе реализован именно
этот вариант. Итак, мы выяснили, что изображение хранится в виде последовательно
идущих "минимальных блоков кодирования", каждый из которых состоит и
блоков 8х8 закодированных значений соответствующей переменной. По поводу
кодирования каждого блока 8х8 смотрите доку. Перечислю лишь шаги:
- Дискретное косинусоидальное преобразование (ДКП)
- зигзагообразная перестановка в массиве 8х8
- квантование
- RLC кодирование нулей
- кодирование Хаффмана.
При этом в массиве 8х8 после ДКП первый элемент [0][0] будет содержать
большую часть информации о всем участке. Поэтому первые элементы кодируются
отдельно, причем кодируется не сами элементы, а разности предыдущего и текущего.
Причем разность не от предыдущего блока вообще, а от предыдущего
блока этой компоненты Например. Пускай для первой MCU первые элементы 4-х
блоков Y компонет равны 64 65 63 64. Первый элемент блока Cb равен 70, первый
элемент блока Cr равен 20. Для следующей MCU первый эл-ты блоков Y компонент
равны 71 72 70 69, Cb - 50, Cr - 30
тогда для кодирования будут получены
разности
| Y |
64 |
1 |
-2 |
1 |
7 |
1 |
-2 |
-1 |
| Cb |
70 |
-20 |
| Cr |
20 |
10 |
Соответственно для расодирования нужно провести эти шаги в обратном
порядке.
1)читаем из заголовка файла таблицы хаффмана и таблицы
квантования.
2)начинаем чтение данных первой MCU.
3)Читаем блок 8х8 первой
компоненты Y.
4)раскодируем используя соответствующую таблицу
Хаффмана.(Таблиц может быть до 4: 2 таблицы для кодирования компоненты Y, одна
для кодирования первого эл-та, другая для кодирования остальных; и две таблицы
для кодирования Cb и Сr.)
5)Проводим обратное квантование.
6)Осуществялем
обратную зигзагообразную перестановку.
7)Проводим обратное Дискретное
косинусоидальное преобразование (ОДКП).
8)Повторяем шаги 3-7 для остальных
блоков MCU: Y, Сb, Cr
9)Реконструируем блок 16х16, проводим преобразование
YCbCr->RGB.
10)выводим полученнй блок, переходим к следующей MCU (шаг
2) или выходим, если достигли конца данных.
Некоторые вещи, не упомянутые
в доках или освещенные неправильно:
- формулки преобразования YCbCr->RGB. В разных источниках даны разные.
Используйте те, что есть в программе.
- DC компоненты (нулевой элемент в массиве 8х8) для разных компонент (Y,Cb,Cr)
свои. Поэтому я заводил массив из трех элементов, первый - DC для Y, второй -
для Cb, третий для Cr, и вычислял очередной DC элемент как сумму предыдущго DC
элемента для этого компоненты цвета и текущей разности.
- Формулка обратного ДКП:
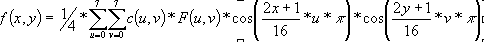
где c(u,v)=1 если u!=0&&v!=0
c(u,v)=1/sqrt(2) если U или v равны нулю, но не одновременно
c(u,v)=1/2
если U==0&&v==0
в некоторых источниках по другому.
Вывод на экран: данные о изображении читаються из файла,
раскодируються если нужно, и на их основе создаеться HBITMAP который затем
выводиться на экран. (для его создания нужно чтобы в буффере данных каждая
строка была выровняна по двойному слову)
Кроме всего вышепеерчисленного прога умеет сохранять изображения в формате
bmp (с глубиной изображения по выбору 8 бит или 24 бита).
Литература по Microsoft Visual C++
|
